如果你的项目使用了 GPL 协议,你大概认为它是一道防线——任何人使用你的代码,就必须把他们的修改也开源出来。但在 AI 代码生成已经成为日常工具的今天,这道防线正在悄悄失效。不是法律改变了,而是技术把法律设计的前提条件破坏掉了。
这篇文章从工程师的视角,拆解 AI 如何通过三条技术路径瓦解开源协议的约束力,梳理目前真实发生的法律攻防,并给出你现在就能部署的应对方案。
目录
- 开源协议的约束力依赖哪些前提?
- 三条瓦解路径
- 真实攻防:GitHub Copilot 诉讼解剖
- 新战场:Rust 复刻潮与许可证降级
- HackerNews 热点:Hermes Agent 抄袭风波与 AI 代码洗白
- 许可证扫描工具为何开始失效
- 现在能做什么:工程侧防御方案
- 下一代开源协议的尝试
- 总结与行动清单
开源协议的约束力依赖哪些前提?
开源协议——尤其是 GPL、AGPL 这类 Copyleft 协议——的执行逻辑建立在三个前提上:
- 代码可溯源:你能识别一段代码来自哪个项目,进而判断它受哪个协议约束。
- 派生关系可认定:你能证明某段代码是对受保护代码的”派生作品”(derivative work)。
- 分发行为可检测:当受保护代码被纳入产品并分发时,你能发现这个事实。
传统工具链(FOSSA、ScanCode、Black Duck)的工作方式就是基于这三点:扫描代码哈希、检测已知片段、追踪文件头注释。这套机制假设代码是”人类写的”,即使被修改,也会留下可识别的结构特征。
AI 代码生成打破的,正是这三个前提。
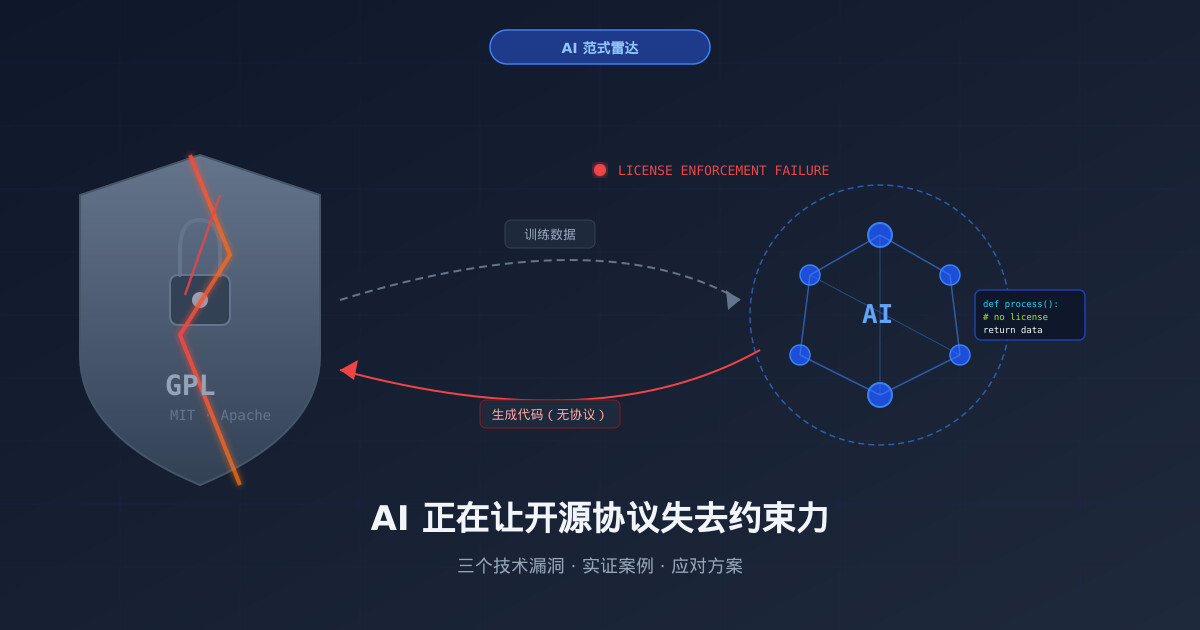
三条瓦解路径
路径一:模型训练吞噬 Copyleft 代码,但不触发协议义务
这是最根本的问题。
GPL 的 Copyleft 传染性设计用于对付”分发”行为——你拿了 GPL 代码,修改后发布,就必须开源你的修改。但 AI 模型训练不是”分发”,而是”学习”。模型读取了数百万行 GPL 代码,把编程模式、算法逻辑、API 用法编码进权重参数——这些权重不是代码的副本,而是代码的统计抽象。
法律学界和工程界对此有一个核心争议:训练后的模型权重是 GPL 代码的”派生作品”吗?
截至 2026 年 5 月,没有任何法院明确裁定”是”。Shujisado 在 2025 年 11 月的分析显示,即使是最激进的 GPL 解释,也很难在技术上证明模型权重”包含”了原始 GPL 代码。结果是:数百万行 Copyleft 代码被用于训练商业模型,模型权重以私有形式分发,原开源社区获得的回馈趋近于零。
这不是某家公司的恶意行为,而是一个系统性的制度漏洞。
路径二:AI 许可证漂白(License Laundering)
这条路径更隐蔽,也更直接地影响你的代码库。
假设你在用 GitHub Copilot 或 Cursor 写代码,请求它实现一个排序算法。模型在内部可能参考了某个 GPL 项目中的实现,生成了一段在功能上高度相似、但在语法上经过重组的代码。这段代码出现在你的 IDE 里时,没有任何许可证标注,没有原作者信息,没有版权声明。
你把它粘贴进项目,提交,发布——许可证信息在这个过程中消失了。这就是”许可证漂白”:借助 AI 作为中间层,把有协议约束的代码变成了看似”干净”的生成代码。
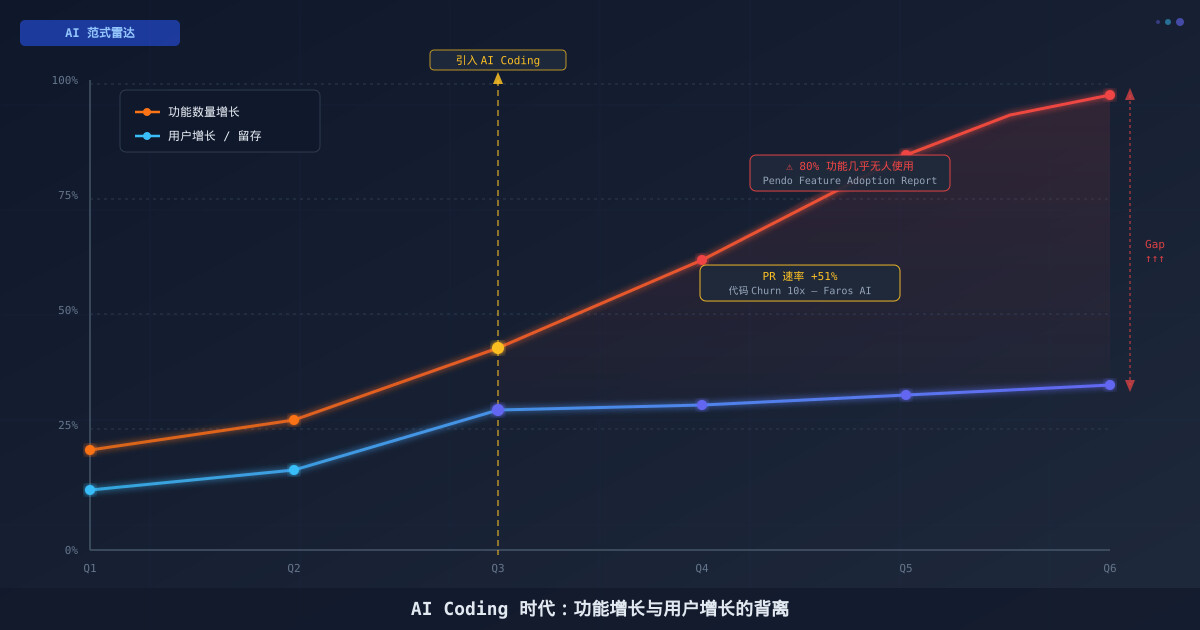
Pickuma 在 2026 年的研究记录了这一现象的规模:68% 的开发者在使用 AI 代码助手时从未检查生成代码的潜在许可证来源,41% 的企业代码审查流程没有针对 AI 生成代码的专项检查步骤。
路径三:DMCA”同一性”标准让维权门槛极高
即使你发现了问题,诉诸法律也面临极高的举证门槛。
2024 年 6 月,加州北区法院在 GitHub Copilot 诉讼(Does v. GitHub)中裁定:要证明 DMCA 版权侵权,原告必须证明生成代码与原始代码”基本相同”(substantially identical)。法官 Jon Tigar 认为原告未能达到这一标准,驳回了主要侵权指控。
问题在于,AI 生成的代码几乎从不逐字复制,它会重新命名变量、调整结构、重新组织逻辑。功能上的相似性很高,但”文本同一性”往往不够。这意味着:用现行法律起诉 AI 许可证侵权,技术上极难胜诉。
真实攻防:GitHub Copilot 诉讼解剖
Does v. GitHub 是迄今最有代表性的 AI 与开源许可证冲突案例,值得仔细看一看。
案件基本情况:
- 2022 年底,一批开源开发者以集体诉讼形式起诉 GitHub、Microsoft 和 OpenAI
- 核心指控:Copilot 在未经许可的情况下,使用公开 GitHub 仓库(含大量 GPL、MIT、Apache 代码)训练模型,并在生成代码时不附带原始许可证信息
诉讼进展:
| 时间 | 事件 | 结果 |
|---|---|---|
| 2022 年底 | 集体诉讼提起 | 指控包括 DMCA 侵权、合同违约、不正当竞争 |
| 2024 年 6 月 | 初审裁定 | 主要 DMCA 指控被驳回(”同一性”标准未达到) |
| 2024 年底 | 剩余指控 | 开源协议违反和合同违约指控继续审理 |
| 2025-2026 | 第九巡回上诉 | 原告就 DMCA”同一性”标准提起上诉,结果待定 |
这个案件的技术意义:
法院的裁定实际上划定了一条线——AI 生成代码只要不逐字复制,就极难在现行 DMCA 框架下被认定为侵权。这对开源社区来说是一个结构性不利判决:你的代码可以在功能上被”借走”,只要 AI 足够”聪明”地做了表面重组。
新战场:Rust 复刻潮与许可证降级
如果说 GitHub Copilot 诉讼展示的是 AI 被动”消化”开源代码,那么 2025 年在 Twitter/X 上持续引爆的 Rust 复刻潮,则暴露了另一条主动规避开源协议的路径——以”高性能重写”为旗号,将 GPL 保护的项目翻译成 MIT/Apache 许可证的 Rust 版本。
案例一:uutils 复刻 GNU Coreutils,GPL v3 → MIT
GNU Coreutils(ls、cp、mv 等几十个核心 Unix 命令)是 GPL v3 授权的。任何基于它的派生作品必须同样以 GPL v3 发布——这是 30 年来阻止商业公司私有化 Linux 基础工具的核心壁垒。
2025 年,uutils/coreutils 项目宣布完成几乎全部命令的 Rust 重写,并选择 MIT 许可证。关键在于它的法律主张:这是独立实现(clean-room rewrite),不是 GNU Coreutils 的派生作品,因此不受 GPL 约束。
Canonical 迅速跟进:Ubuntu 25.10 开始以 uutils 替换 GNU Coreutils,Ubuntu 26.04 LTS(2026 年 4 月发布)计划完成全面切换(cp、mv、rm 因安全审计延迟,其余已完成)。如果 Debian 也跟进,MIT 授权的 Rust 工具将成为数亿台 Linux 服务器的默认基础设施——届时 GPL v3 对这些命令的保护将事实上终结。
Twitter/X 上的反应两极分化。支持者认为 Rust 的内存安全性是技术进步,反对者则将其称为”开源自由的特洛伊木马”:
“uutils is MIT, not GPL. That means any company can take it, modify it, and never release their changes. That’s the whole point of copyleft. Ubuntu is shipping a backdoor to privatization.”
— 推文,2025 年 9 月,获数千次转发
案例二:Rust 基金会商标政策,变相封杀 GPL 项目
2025 年底,Rust 基金会发布新商标政策:GPL 授权的项目不得在未经基金会审批的情况下在名称或营销中使用”Rust”品牌。这一政策的背后,是 Rust 基金会的主要赞助商——Google、Microsoft、AWS、Meta——这些公司在其内部大规模 Rust 项目中均优先选择 MIT 或 Apache 2.0 授权,对 GPL 的”传染性”深感忌惮。
批评者的结论很直接:这不是商标管理,而是用品牌权来施压整个 Rust 生态系统远离 Copyleft。这是协议约束力被侵蚀的另一种形式——不通过法律漏洞,而是通过生态系统控制权。
案例三:AI 加速了”高性能复刻”的成本结构
上述案例中 AI 扮演了什么角色?答案是:AI 大幅降低了 clean-room rewrite 的成本,使其从几年的工程量压缩到几个月甚至几周。
2025 年 12 月,微软一位杰出工程师 Galen Hunt 在 LinkedIn 发帖,声称微软正在开发 AI 辅助的 Rust 迁移技术,目标是实现”1 名工程师、1 个月、100 万行代码”的迁移速度。这条帖子在 Twitter/X 上迅速引爆,被解读为”微软要用 AI 把 Windows 重写成 Rust”。微软随后紧急澄清这是研究项目,但真正值得关注的信号是:AI 让 clean-room rewrite 的声称变得更容易,让”这是 AI 独立生成的,不是 GPL 代码的派生物”这一法律抗辩更具操作空间。
以下是这条路径的完整逻辑链:
GPL 项目(C/C++)
↓ AI 辅助翻译("clean-room" 声称)
Rust 重写版(MIT/Apache)
↓ 功能等价,但许可证断开
商业采用,不需要开源修改
这与路径二(AI 许可证漂白)在结构上完全相同,区别只是规模:一次漂白的不是一个函数,而是一整个项目的协议义务。
这对工程师意味着什么
| 场景 | GPL 的期望保护 | Rust 复刻路径的实际结果 |
|---|---|---|
| 有人使用你的 GPL 代码 | 必须以 GPL 发布修改 | 用 AI 重写,声称不是派生,MIT 发布 |
| 发行版使用你的 GPL 工具 | 用户获得 GPL 保护的版本 | 发行版切换到 MIT Rust 版,保护解除 |
| 你的项目被商业化 | 必须开源商业版本 | 基于 Rust 重写版的商业分支,无开源义务 |
在还没有法院明确裁定”AI 辅助 clean-room rewrite 是否构成派生作品”之前,这扇门是敞开的。
HackerNews 热点:Hermes Agent 抄袭风波与 AI 代码洗白
如果说 Rust 复刻是”项目级许可证漂白”,那么 2026 年 3 月在 HackerNews 和 Twitter/X 上引爆的 Hermes Agent 事件,则让一个新概念进入了工程师社区的视野:AI 代码洗白(AI Code Washing)——借助 AI 工具对架构级别的复制进行表面重写,使其看起来像独立实现。
事件经过
时间线:
| 日期 | 事件 |
|---|---|
| 2026 年 2 月 1 日 | 中国 AI 团队 EvoMap 在 MIT 协议下开源 Evolver(自进化 Agent 引擎) |
| 2026 年 3 月 9 日 | 硅谷明星实验室 Nous Research 发布 Hermes Agent 自进化模块 |
| 2026 年 3 月中旬 | EvoMap 发布详细技术对比报告,指控 Hermes Agent 抄袭核心架构 |
| 2026 年 3 月下旬 | Nous Research 创始人 Teknium 否认知晓 EvoMap,回应引发争议 |
| 2026 年 3 月末 | EvoMap 将 Evolver 许可证从 MIT 切换为 GPL v3,并开始混淆核心代码 |
EvoMap 提交的证据:
- 10 步核心循环完全一致:Evolver(Node.js)与 Hermes Agent(Python)的自进化主循环在逻辑步骤上一一对应,尽管语言不同;
- 12 对核心术语被系统性替换:例如
Evolver→FunctionCalling、Gene→Skill、Mutation→Refinement——名称不同,但概念映射关系完全保留; - 无任何引用或致谢:Hermes Agent 的代码注释、README 和论文均未提及 Evolver。
这在技术社区引发了一个核心问题:当两个系统用不同语言实现了相同的 10 步架构,且关键术语一一对应,这是”独立发现”还是”架构抄袭”?
AI 代码洗白:新瓦解路径
Hermes Agent 事件让”AI 代码洗白”这个概念具象化。这条路径的操作逻辑如下:
MIT 开源项目(Node.js 实现,含架构创新)
↓ AI 辅助跨语言重写(Python)
术语系统性替换(Gene→Skill, Evolver→FunctionCalling)
↓ 逻辑关系保留,表面代码全部不同
发布为"独立创新",无需引用,无协议义务
这与路径二(AI 许可证漂白)的区别在于粒度:许可证漂白发生在函数/片段级别,而 AI 代码洗白可以作用于整个系统的架构逻辑——而目前所有许可证文本只保护”表达”(expression),不保护”思想”(idea)。这正是版权法的”思想-表达二分法”(Idea-Expression Dichotomy)在 AI 时代遭遇的最大挑战之一。
开源社区的反应与连锁效应
事件在 HackerNews 上的讨论帖获得数百条回复,主要争论点集中在:
- “架构级抄袭”是否在现行法律下构成侵权? 多数法律评论者认为:很可能不构成——版权不保护算法思想,只保护具体代码表达;
- MIT 协议是否对此类行为无能为力? 结论是:是的,MIT 协议完全没有防御此类架构复制的条款;
- Nous Research 的应对方式是否损害了开源信任? 社区对此批评尤为强烈,认为无论是否存在法律责任,对小团队创新成果的致谢是开源规范的基本要求。
EvoMap 的应对选择——从 MIT 切换到 GPL v3 并混淆代码——代表了越来越多受到类似冲击的小团队的心理轨迹:不是因为 GPL 能防住这种行为(它同样不能),而是表达一种态度,并让下一次复制付出更高成本。
这个结果具有讽刺意味:开源社区最害怕的不是法律失效,而是规范失效——当足够多的团队因担忧架构抄袭而关闭源码或切换到 Copyleft,整个 AI 开源生态的开放性都会收缩。
许可证扫描工具为何开始失效
你可能已经在 CI/CD 流水线里部署了 FOSSA 或 ScanCode,认为这给了你足够的保护。在 AI 代码生成普及之前,这个判断基本正确。现在,这套工具面临三个新的盲区:
盲区一:基于哈希的检测失效
传统工具的核心方法是文件哈希比对和代码片段匹配。AI 生成的代码即使逻辑上来自受保护的源代码,在字节层面几乎总是不同的。ScanCode 的规则引擎设计用于检测复制粘贴,对 AI “理解后重写”的输出几乎无效。
盲区二:无法追踪生成来源
扫描工具能告诉你”这段代码有 MIT 许可证”,但无法告诉你”这段 AI 生成的代码,其逻辑来自哪个训练样本”。AI 模型本身也不能可靠地回答这个问题——即使是 GitHub Copilot 的企业版”代码引用”(code citations)功能,也只能捕获近似逐字引用,对经过重组的输出无能为力。
盲区三:速度与规模不匹配
一个熟练使用 AI 助手的工程师,每天产出的代码量可能是传统方式的 3-5 倍。传统的人工代码审查流程没有针对 AI 生成内容的专项检查步骤,而自动化工具又存在上述盲区——这就产生了一个实质性的合规缺口。
现在能做什么:工程侧防御方案
面对这些漏洞,完全被动等待法律跟上不是工程师应有的姿态。以下是你现在就能部署的技术方案。
方案一:在 AI 工具层设置许可证过滤
主流 AI 代码助手的企业版都提供了某种程度的许可证控制:
# GitHub Copilot Enterprise - 代码引用配置
# .github/copilot-settings.yml
copilot:
content_exclusions:
# 排除特定路径不作为上下文
- "vendor/**"
- "third_party/**"
# 启用代码引用检测(当生成代码与公开代码高度相似时提示)
duplication_detection: true
对于 Cursor 等工具,可以通过 .cursorignore 限制模型对敏感文件夹的访问,减少 Copyleft 代码进入上下文的概率。
重要提示:这些功能只能降低风险,无法消除。它们依赖模型自报潜在引用,而模型并不总能准确识别。
方案二:引入 AI 生成代码的专项审查步骤
在代码审查流程中,增加针对 AI 生成代码的专项检查。一个实用的做法是在提交信息中标注 AI 辅助内容:
# 团队约定:使用 AI 助手生成的代码,提交时加 [AI] 标注
git commit -m "[AI] implement binary search with early termination
Generated with Cursor/Claude. Reviewed for logic correctness.
License origin: unknown - flagged for compliance review."
然后在 CI 中设置规则,对包含 [AI] 标注的提交触发额外的许可证扫描和人工复核:
# .github/scripts/check_ai_commits.py
import subprocess
import sys
def check_ai_commits():
"""检查 PR 中是否包含 AI 生成代码,如有则触发额外审查"""
result = subprocess.run(
['git', 'log', '--oneline', 'origin/main..HEAD'],
capture_output=True, text=True
)
commits = result.stdout.strip().split('\n')
ai_commits = [c for c in commits if '[AI]' in c or '[ai]' in c.lower()]
if ai_commits:
print(f"发现 {len(ai_commits)} 个 AI 辅助提交,触发许可证合规审查:")
for c in ai_commits:
print(f" - {c}")
# 在 CI 中触发额外的许可证扫描步骤
sys.exit(2) # exit code 2 = 需要额外审查,非错误
print("未发现 AI 辅助提交,常规扫描通过。")
sys.exit(0)
if __name__ == '__main__':
check_ai_commits()
方案三:使用语义相似度扫描补充传统工具
传统哈希匹配失效,但语义相似度检测仍然有效。工具如 Sourcegraph 的代码搜索,或基于向量嵌入的相似度检测,可以识别逻辑上相似但语法不同的代码片段:
# 使用 tree-sitter 提取 AST,再做语义相似度比较
# 这比基于文本的比较更能识别 AI 重写后的代码
from tree_sitter import Language, Parser
import hashlib
def extract_ast_fingerprint(code: str, language: str = 'python') -> str:
"""
提取代码的 AST 指纹,用于语义相似度比较。
变量名、注释等表面变化不影响指纹,但逻辑结构改变会反映出来。
"""
# 初始化 parser(需要预编译对应语言的 grammar)
PY_LANGUAGE = Language('build/my-languages.so', language)
parser = Parser()
parser.set_language(PY_LANGUAGE)
tree = parser.parse(bytes(code, 'utf-8'))
# 提取节点类型序列作为结构指纹(忽略标识符名称)
node_types = []
def traverse(node):
node_types.append(node.type)
for child in node.children:
traverse(child)
traverse(tree.root_node)
fingerprint_str = ','.join(node_types)
return hashlib.sha256(fingerprint_str.encode()).hexdigest()[:16]
这个方向还不成熟,但已经有商业工具(Synopsys Black Duck 2025 版、Snyk 的 AI 代码溯源模块)开始提供类似能力。
方案四:项目层面的许可证策略调整
如果你是开源项目维护者,可以考虑主动调整协议策略来应对 AI 训练场景:
- 切换到 AGPL:对于 Web 服务场景,AGPL 要求即使以服务形式使用也需要开源,在一定程度上覆盖了 AI 推理服务的场景(但对训练仍无效)
- 添加 Commons Clause:在 Apache/MIT 基础上附加”不得将本软件用于训练 AI 模型”的商业限制条款(这会使项目不再符合 OSI 的开源定义,需要权衡)
- 采用 Server Side Public License (SSPL):MongoDB 使用的许可证,约束范围更广,但同样不被 OSI 认可为”开源”
下一代开源协议的尝试
社区正在尝试从协议设计层面堵上这个漏洞。
Contextual Copyleft AI (CCAI):由法律学者提出(arXiv:2507.12713),核心思路是将 Copyleft 义务从”分发代码”扩展到”使用代码训练模型”——任何使用 CCAI 授权代码训练的 AI 模型,其权重必须以同等开放的形式发布。这个方向在技术上合理,但执行层面面临巨大挑战:如何证明某个模型确实使用了某份 CCAI 代码训练?
RAIL (Responsible AI Licenses):已被 BigScience、Hugging Face 等采用,核心是在许可证中加入”使用限制”条款,禁止特定用途(如生成有害内容、监控)。但 RAIL 不要求训练数据开源,解决的是不同的问题。
OpenRAIL-S:专门针对模型权重的许可证,允许商业使用但限制特定有害应用。Stability AI、BigScience 的 BLOOM 模型都在使用。
这些新协议都还处于早期阶段,法律效力有待验证,行业采用率也有限。但它们代表了开源社区面对 AI 范式冲击的主动探索。
总结与行动清单
开源协议的约束力正在被四个技术事实系统性地削弱:AI 训练不触发 Copyleft 传染、AI 生成过程清洗掉许可证信息、现行法律的举证标准与 AI 生成代码的特点不匹配、以及 AI 加速的”clean-room rewrite”让整个项目的协议义务可以被一次性抹除。Rust 复刻潮是这一结构性侵蚀最近最热的体现,Hermes Agent 事件则进一步揭示了协议之外的规范层失效——法律保护不了的架构创新,现在连社区信任也开始无法保护了。
作为工程师和开源贡献者,被动等待法律跟上不是选项。
你现在可以做的:
- 审视你的 AI 工具配置:开启 GitHub Copilot Enterprise 的代码引用检测;在 Cursor/Windsurf 中设置
.cursorignore排除含 Copyleft 代码的目录 - 建立 AI 代码标注约定:团队内统一使用
[AI]前缀标注 AI 辅助提交,并在 CI 中触发额外的合规检查 - 升级你的许可证扫描工具:评估 Synopsys Black Duck 和 Snyk 的 AI 代码溯源模块,2025 年版本开始提供语义级别的相似度检测
- 重新评估你的开源协议选择:如果项目的核心价值在于 Copyleft 传播,认真考虑 AGPL;如果主要担忧是商业竞争,Commons Clause 是一个现实选项
- 追踪”高性能 Rust 复刻”趋势:如果你维护的 GPL 项目已有 Rust 实现版本,评估其许可证差异及法律地位;如果其宣称”clean-room rewrite”,考虑与法律顾问确认该主张的可诉性
- 关注 CCAI 和 EU AI Act 进展:欧盟 AI 法案中的训练数据透明度条款(预计 2027 年生效)可能在监管层面提供部分保护
References
- Does v. GitHub 诉讼进展
- AI 许可证漂白:代码生成器如何剥离开源归属
- GPL 是否传染 AI 模型权重?法律现状分析(2025)
- Contextual Copyleft AI 许可证提案论文
- 开源代码训练:GPL/MIT 等协议真正说了什么(2025 详解)
- GitHub Copilot AI 与 IP 法律洞察
- uutils Rust coreutils 替换 GNU Coreutils 争议——Ubuntu 社区讨论
- Ubuntu 25.10 计划以 Rust 替换 GNU Coreutils — The Register
- Rust 基金会禁止 GPL 项目使用 Rust 品牌:企业控制开源?
- 微软工程师”1 人 1 月 100 万行 Rust 迁移”事件始末
- Hermes Agent 抄袭风波:硅谷明星项目陷入争议
- EvoMap 将 Evolver 许可证从 MIT 切换 GPL v3 的声明
- Hermes Agent 事件技术真相与开源危机深度分析


 一分钟读论文:《多智能体什么时候该用、什么时候不该用?》
一分钟读论文:《多智能体什么时候该用、什么时候不该用?》