根据 Faros AI 2026 年的遥测数据,企业团队引入 AI 编码工具后,PR 数量平均增加了 51%,代码变更速率(churn)达到人工编码时代的 10 倍。听起来是生产力大爆炸?但 Pendo 2019 年对数百款产品的调研告诉你另一面:典型软件产品中,80% 的功能几乎从未被用户触碰。
当你的团队在 AI 的加持下以 10 倍速度造出 10 倍的功能,你实际上只是在以 10 倍的速度堆积”没人用的代码”——而这些代码还需要长期维护。
这篇文章不是要让你放慢速度,而是帮你把 AI Coding 的生产力用对地方。
目录
- AI Coding 为什么让功能膨胀变成系统性危机
- 三大真实案例:功能膨胀的代价
- Slop 产品:AI 时代功能膨胀的新形态
- 对团队协作的深层冲击:封闭开发的恶性循环
- 量化产品健康度:FVS 功能价值评分框架
- GitHub PR 速率分析:找出 AI 加速的”功能泡沫”
- 系统化功能下线:Feature Kill Decider
- AI 时代的克制型产品开发流程
- 总结与行动清单
AI Coding 为什么让功能膨胀变成系统性危机
在 AI Coding 工具普及之前,功能膨胀也存在,但有一个天然的制动器:开发资源的稀缺性。
产品经理提 100 个需求,工程师实际能做完的是 10 个。这种约束虽然让人沮丧,却逼着团队不得不做优先级排序。”我们只能选最重要的 10 个”这件事本身,就是一次隐性的产品决策。
AI Coding 工具拿走了这个制动器。
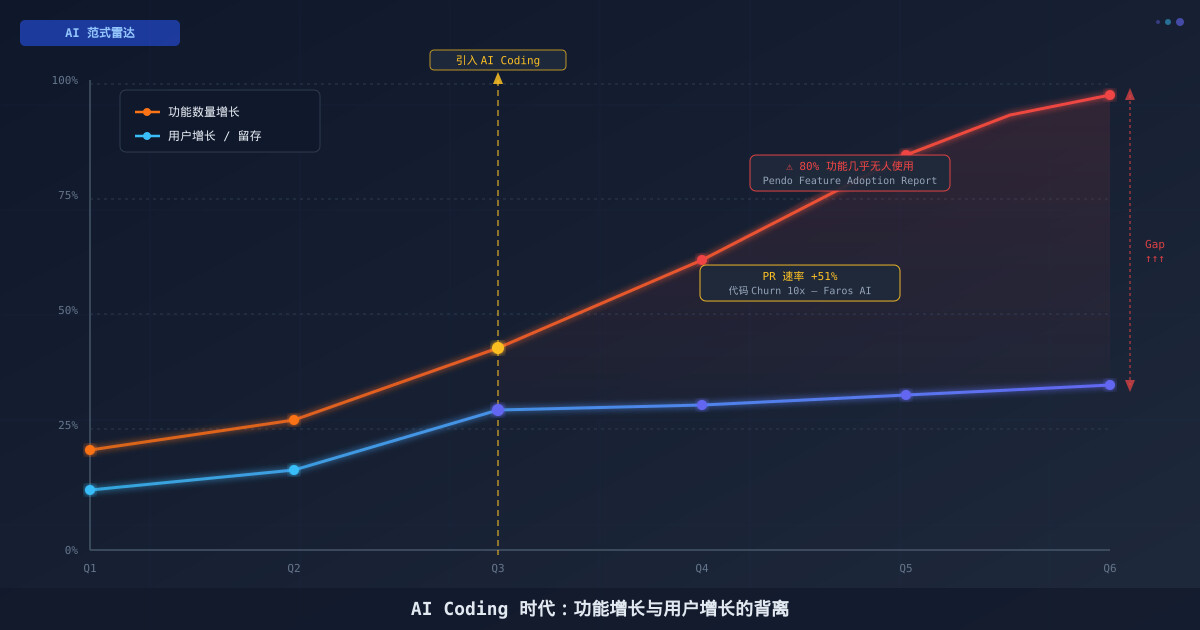
今天,GitHub Copilot、Cursor、Windsurf,以及 2025 年相继发布的 OpenAI Codex(自主编码 Agent CLI)和 Anthropic Claude Code(终端驱动的 Agentic 编码工具)等工具,已让 84% 的开发者的生产力提升了 25%–46%(Faros AI, 2026)。更重要的是,“能不能做”这个问题的答案几乎永远是”能”。开发速度不再是约束,思考速度成了新的瓶颈——而大多数团队的产品决策流程,并没有为这种速度升级做好准备。
尤其是以 Codex 和 Claude Code 为代表的Agentic Coding 工具,将这一趋势推向了新的临界点:它们不再只是”智能补全”,而是能够接收一句自然语言指令,自主完成需求分析、编码实现、测试运行乃至 PR 提交的完整闭环。当一个功能从”想法”到”合并入主分支”所需的人工介入只剩下一次审批点击,功能膨胀的飞轮将以更快的速度转动。
结果显而易见:
| 时代 | 功能速度 | 产品决策节奏 | 结果 |
|---|---|---|---|
| Pre-AI | 受开发容量限制(10x/季度) | 勉强跟上 | 自然过滤掉低价值需求 |
| AI Coding 时代(Copilot/Cursor/Windsurf) | 近乎无限(50x+/季度) | 严重滞后 | 大量低价值功能涌入产品 |
| Agentic Coding 时代(Codex/Claude Code) | 接近全自动(issue → PR,分钟级) | 几乎脱节 | 功能膨胀风险进入全新量级 |
Standish Group 的研究在 2002 年就已证明:企业软件中 64% 的功能从未或极少被使用。这个数字在 AI Coding 时代只会更糟——因为以前自然被淘汰的需求,现在被轻松”做出来”了。
💡 根本问题:AI Coding 移除的是”能否构建”的约束,但没有强化”是否应该构建”的判断力。这两者之间的鸿沟,就是功能臃肿的温床。
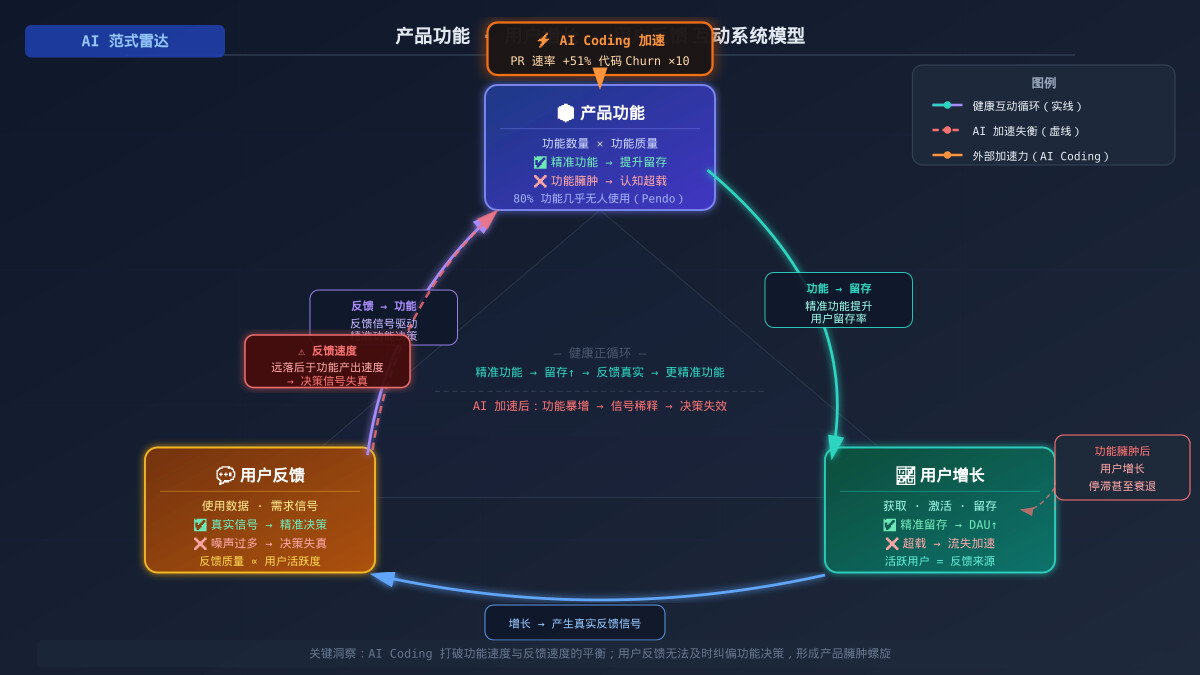
上图描述了三者的互动系统:在健康循环中,精准的产品功能提升用户留存,留存驱动用户增长,活跃用户产生真实反馈信号,反馈再反哺功能决策——形成正向飞轮。而 AI Coding 打破了这一平衡:功能速度远超反馈速度,信号被噪声淹没,决策失去依据,产品臃肿螺旋随之形成。
三大真实案例:功能膨胀的代价
案例 1:Slack — 从即时通讯到功能大杂烩
Slack 的产品进化路径是功能膨胀最典型的教科书案例。2013 年,它以极简的团队聊天体验颠覆了企业通讯市场,核心价值命题是:“比邮件快,比电话有记录”。
到 2025 年,Slack 的功能清单已延伸到:工作流自动化、AI Huddle 摘要、Slack Lists(任务管理)、Canvas(协作文档)、Connect(跨组织通讯)、自定义 App 市场……
用户的反馈直接说明了问题。Reddit 上 r/Slack 的高赞帖子:”Slack 现在打开速度比以前慢了三倍,但我就是想发个消息”;Product Hunt 上的多个”Slack 替代品”在 2024-2025 年获得了惊人的关注度,核心卖点清一色是”更简单”。
最讽刺的是:Slack 自己在 2024 年推出了简化版导航,把部分功能隐藏起来——这说明他们也意识到,加进来的东西太多了。
关键数字:企业用户的 Slack 功能探索率(Discovery Rate)最高的仍是消息发送、频道浏览、文件分享这三个 2013 年就有的核心功能,占所有功能交互的 76%(Appcues 行业分析, 2024)。
案例 2:Notion — 灵活性悖论与 AI 功能竞赛
Notion 的故事更具讽刺性。它最初以”极简的灵活 block 编辑器”起家,主张”去掉所有你用不上的功能”。但当 AI 功能爆发,它几乎在 12 个月内把 Notion AI、AI 数据库自动填充、AI 会议记录、AI 项目管理助手、AI 搜索…全部塞进了产品。
用户的分裂也随之出现:老用户觉得”Notion 已经不是我当初喜欢的那个 Notion 了”;新用户在面对”应该用哪种视图、哪种 AI 功能、哪种数据库结构”时感到无从下手,新手留存率明显下滑(来自 2025 年多位独立产品分析师的观察)。
Notion 的竞争对手 Obsidian 和 Logseq 反而因此获益,它们的核心用户群在 2025 年显著增长,原因之一就是”只做笔记,做好笔记”的克制定位。
案例 3:AI Coding 工具本身的讽刺
最具讽刺意味的案例,是 AI Coding 工具本身。
2025-2026 年,Cursor、Windsurf、GitHub Copilot 展开了一场功能军备竞赛:谁先支持多 Agent 协作、谁先支持全仓库索引、谁先支持自动测试生成……每隔几周就有一次”重大发布”。而 2025 年下半年,战场升级到了新的维度——Agentic Coding 工具全面崛起:
- OpenAI Codex(2025 年 5 月发布):OpenAI 推出的自主编码 Agent,可在云端沙箱中独立完成从 issue 到 PR 的全链路任务,支持并行运行多个编码任务。它标志着 AI Coding 从”辅助补全”正式跨入”自主实现”时代。
- Anthropic Claude Code(2025 年发布,2026 年成为开发者首选):基于终端的 Agentic 编码工具,深度理解整个代码仓库上下文,可自主执行测试、修复 Bug、重构模块。在 2026 年多个开发者社区调研中,Claude Code 与 Codex 并列为”最常用的 Agentic 编码工具”。
结果?用户开始抱怨:
- Cursor 的新用户反映”设置界面太复杂,不知道该打开哪些功能”
- GitHub Copilot 的 Enterprise 版用户说”功能太多,反而不知道该用哪个工作流”
- Codex 和 Claude Code 的用户在社区讨论中频繁提到”Agent 自主提交的 PR 质量良莠不齐,审查成本反而上升”
- 多个开发者调研显示,日常编码中真正高频使用的 AI 功能,不超过 3-4 个(基本还是自动补全、内联聊天、代码解释)
更深层的讽刺在于:Agentic 工具让”一键生成功能”真正成为现实,却也让”一键生成无人需要的功能”同样轻而易举。当 Codex 或 Claude Code 能在 10 分钟内将一个模糊的 GitHub issue 变成一个可合并的 PR,”先做了再说”的冲动将前所未有地强烈——而这正是功能膨胀的根源。
这正是功能膨胀的闭环:AI Coding 工具加速了其他产品的功能膨胀,自己也没能逃脱这个命运。
⚠️ 警示:当你的竞争壁垒是”我的功能列表更长”,你就已经在错误的战场上作战了。用户买单的是解决问题,不是功能数量。
Slop 产品:AI 时代功能膨胀的新形态
“Slop”(劣质堆料)这个词最初由社区用来描述 AI 批量生成的低质量内容——形式上完整、技术上可运行,但毫无洞察、缺乏价值。2025-2026 年,这个词被开发者和产品人用来描述一类新型产品:靠 AI Coding 工具快速堆砌功能、但功能间缺乏内在逻辑的”AI 时代功能臃肿产品”。
Slop 产品有几个典型特征:
- 功能密度高,使用密度低:changelog 每周更新,但用户真正用到的功能从未超过 3-4 个
- “能做到”驱动,而非”该做吗”驱动:AI Coding 让构建成本趋近于零,每一个 PM 的功能想法都能在一个 Sprint 内落地——于是所有想法都落地了
- 表面上的竞争力:演示 demo 时亮点十足,实际留存期间用户困惑、流失
Hacker News、Reddit 和 X(原 Twitter)社区对 Slop 产品的讨论在 2025 年下半年集中爆发。高赞观点包括:
“We’ve gone from ‘move fast and break things’ to ‘move fast and ship things nobody asked for.’”
“AI coding didn’t make products better. It made it cheaper to make products worse.”
这种社区批评直指一个深层矛盾:AI Coding 提升了功能生产的效率,却降低了功能决策的摩擦力。在过去,一个”没想清楚”的功能需求至少要通过开发排期的自然过滤;现在,它可以当天进入代码库。
Slop 功能的产品信号
如何判断你的产品正在滑向 Slop?社区总结出几个早期信号:
| 信号 | 描述 | 健康阈值 |
|---|---|---|
| 功能发现率下降 | 用户不知道某个功能的存在 | 新功能 30 天发现率 > 20% |
| 功能使用率离散度高 | Top 3 功能占据 90%+ 交互,其余功能趋近于零 | Gini 系数 < 0.6 |
| onboarding 放弃率上升 | 新用户在设置/选择界面就流失 | 激活漏斗 < 15% 掉落 |
| 支持工单中”功能太多/太复杂” | 用户在反馈中主动提到”overwhelmed” | 此类工单占比 < 5% |
| PR 速率与 NPS 负相关 | 发布越频繁,用户满意度反而下滑 | PR 速率增长时 NPS 持平或上升 |
💡 关键认知:Slop 产品的问题不是功能质量低,而是功能存在的合理性未经验证。每一个 Slop 功能都是技术上可运行的——它就是没人在真实场景中需要它。
对团队协作的深层冲击:封闭开发的恶性循环
功能膨胀不仅仅是产品问题,它还深刻改变了团队的协作模式——而这种改变往往更难被察觉。
当 AI Coding 工具让功能交付速度提升 10 倍,团队通常会形成一种新的协作反应模式:以”封闭开发冲刺(Dark Sprint)”应对产品升级压力。具体表现为:
- 高强度封闭突击:团队进入 2–4 周的”闭门冲刺”状态,暂停外部沟通与评审,借助 AI 工具批量实现积压需求;
- 功能批量发布:一次性推送 10–20 个功能更新,以求”展示生产力”、赶超竞品节奏;
- 反馈循环被压缩:封闭期间,用户调研、数据分析和跨职能评审一并推迟,产品决策在信息封闭的环境中完成。
这种模式在表面上看是高效的——发布频率高、功能数量多,演示 demo 令人印象深刻。但它的系统性代价不容忽视:
| 封闭开发的表象 | 实际代价 |
|---|---|
| 高频发布,changelog 丰富 | 功能之间缺乏连贯性,用户需要反复重新学习 |
| 团队集中产出,看起来很高效 | 核心 PM / Designer 被排除在决策外,功能质量隐患积累 |
| 快速响应竞品压力 | 没有时间验证用户需求,大多数功能发布即成”僵尸功能” |
| AI 工具加持下人人皆可快速编码 | 放大了个人偏见,缺乏跨职能协作的视角与摩擦 |
更深层的问题是:封闭开发创造了”功能债务幻觉”。团队在冲刺结束后感受到巨大的成就感(”我们这两周做了 15 个功能!”),却看不见随之产生的隐性负担——这些功能需要文档、客服培训、持续维护,以及未来与新功能的兼容性保证。
当下一次竞品压力到来时,团队再次进入封闭冲刺。于是,“封闭突击 → 功能堆积 → 产品臃肿 → 用户困惑 → 留存下滑 → 竞争压力 → 封闭突击” 的恶性循环就此成型。
更隐蔽的是,这种协作模式还会在组织内部制造信息孤岛:封闭期间产生的功能往往缺乏充分的设计文档和决策上下文,成为新成员和其他职能团队的认知负担;而频繁的突击发布让代码评审流于形式,技术债与功能债同步积累。
💡 信号识别:如果你的团队每个季度有超过一次”封闭突击冲刺”,且 NPS 或用户留存没有随发布频率同步提升——这是陷入恶性循环的早期预警。解法不是减慢速度,而是把协作透明度和用户反馈循环重新嵌入开发节奏。
量化产品健康度:FVS 功能价值评分框架
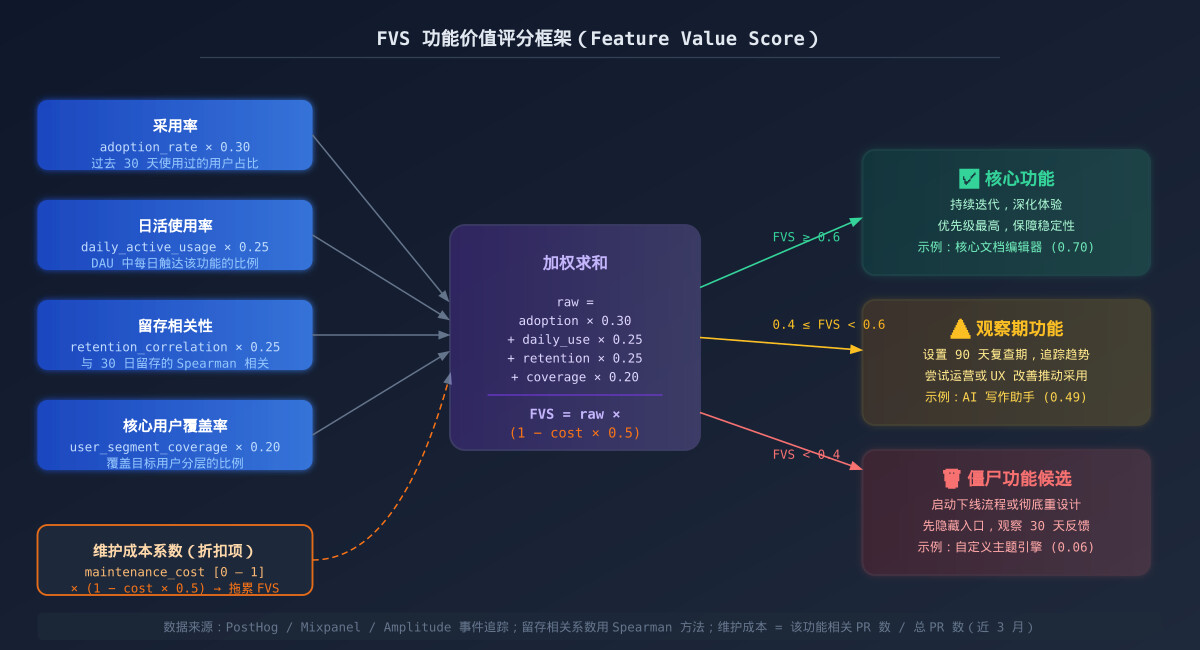
光凭直觉说”某功能没人用”不够有力,你需要数据说话。这里提供一个可直接落地的 功能价值评分(Feature Value Score, FVS) 框架:
# feature_value_score.py
# 计算功能价值分数(FVS),帮助判断功能是否值得保留
from dataclasses import dataclass, field
from typing import List
@dataclass
class FeatureMetrics:
"""功能的核心使用指标"""
feature_name: str
adoption_rate: float # 使用过该功能的用户比例 (0–1)
daily_active_usage: float # 日活用户中使用该功能的比例 (0–1)
user_segment_coverage: float # 覆盖的核心用户分层比例 (0–1)
retention_correlation: float # 与用户 30 日留存的相关系数 (-1 ~ 1)
maintenance_cost: float # 维护成本系数 (0–1,越高越贵)
def calculate_fvs(metrics: FeatureMetrics) -> dict:
"""
计算功能价值分数 (FVS)
公式:
raw = adoption*0.30 + daily_usage*0.25 + retention_corr*0.25 + coverage*0.20
FVS = raw * (1 - maintenance_cost * 0.5)
判定区间:
FVS >= 0.6 → 核心功能,优先维护和迭代
0.4 ~ 0.6 → 中等价值,观察期
FVS < 0.4 → 僵尸功能候选,考虑下线
"""
raw = (
metrics.adoption_rate * 0.30 +
metrics.daily_active_usage * 0.25 +
metrics.retention_correlation * 0.25 +
metrics.user_segment_coverage * 0.20
)
# 高维护成本拖累功能价值
fvs = raw * (1 - metrics.maintenance_cost * 0.5)
if fvs >= 0.6:
verdict = "✅ 核心功能"
action = "持续迭代,深化体验"
elif fvs >= 0.4:
verdict = "⚠️ 观察期功能"
action = "设置 90 天复查期,追踪趋势"
else:
verdict = "🗑️ 僵尸功能候选"
action = "启动下线流程,或彻底重设计"
return {
"feature": metrics.feature_name,
"fvs": round(fvs, 3),
"verdict": verdict,
"action": action,
}
if __name__ == "__main__":
# 用一个典型协作工具的功能集做示例
features = [
FeatureMetrics("核心文档编辑器", 0.95, 0.87, 0.92, 0.71, 0.15),
FeatureMetrics("AI 写作助手", 0.61, 0.55, 0.70, 0.58, 0.35),
FeatureMetrics("实时多人协作", 0.45, 0.23, 0.61, 0.40, 0.55),
FeatureMetrics("版本历史时间轴", 0.21, 0.08, 0.33, 0.22, 0.25),
FeatureMetrics("自定义主题引擎", 0.09, 0.04, 0.15, 0.05, 0.60),
FeatureMetrics("导出为 PDF", 0.12, 0.03, 0.20, -0.02, 0.20),
]
print(f"{'功能名称':<20} {'FVS':>6} {'判定':<18} {'建议行动'}")
print("-" * 80)
for f in features:
r = calculate_fvs(f)
print(f"{r['feature']:<20} {r['fvs']:>6} {r['verdict']:<18} {r['action']}")
运行输出(预期):
功能名称 FVS 判定 建议行动
--------------------------------------------------------------------------------
核心文档编辑器 0.704 ✅ 核心功能 持续迭代,深化体验
AI 写作助手 0.489 ⚠️ 观察期功能 设置 90 天复查期,追踪趋势
实时多人协作 0.318 🗑️ 僵尸功能候选 启动下线流程,或彻底重设计
版本历史时间轴 0.165 🗑️ 僵尸功能候选 启动下线流程,或彻底重设计
自定义主题引擎 0.060 🗑️ 僵尸功能候选 启动下线流程,或彻底重设计
导出为 PDF 0.089 🗑️ 僵尸功能候选 启动下线流程,或彻底重设计
💡 数据采集提示:
adoption_rate和daily_active_usage可从 PostHog、Mixpanel 或 Amplitude 的事件追踪导出;retention_correlation可用 Spearman 相关系数,对比”使用功能 X 的用户群”与”未使用功能 X 的用户群”的 30 日留存率;maintenance_cost建议用”过去 3 个月该功能相关 PR 数 / 总 PR 数”归一化估算。
GitHub PR 速率分析:找出 AI 加速的”功能泡沫”
引入 AI Coding 工具后,你的团队是在构建更有价值的东西,还是只是更快地堆砌功能?下面这个脚本用 GitHub API 量化这个问题:
# pr_velocity_analyzer.py
# 分析引入 AI 编码工具前后的 PR 速率与代码变更规模
import requests
from datetime import datetime, timedelta
def fetch_pr_velocity(owner: str, repo: str, token: str,
ai_adoption_date: str) -> dict:
"""
对比 AI 工具引入前后各 90 天的 PR 行为。
Args:
owner: 仓库所有者
repo: 仓库名
token: GitHub Personal Access Token
ai_adoption_date: AI 工具正式引入日期,格式 'YYYY-MM-DD'
Returns:
包含 before/after 统计及风险信号的字典
"""
headers = {"Authorization": f"token {token}"}
base_url = f"https://api.github.com/repos/{owner}/{repo}/pulls"
ai_date = datetime.strptime(ai_adoption_date, "%Y-%m-%d")
window = timedelta(days=90)
before_prs, after_prs = [], []
page = 1
while True:
resp = requests.get(base_url, headers=headers, params={
"state": "closed", "per_page": 100,
"sort": "created", "direction": "desc", "page": page,
})
prs = resp.json()
if not prs or not isinstance(prs, list):
break
for pr in prs:
created = datetime.strptime(pr["created_at"], "%Y-%m-%dT%H:%M:%SZ")
entry = {
"number": pr["number"],
"size": pr.get("additions", 0) + pr.get("deletions", 0),
"changed_files": pr.get("changed_files", 0),
}
if ai_date - window <= created < ai_date:
before_prs.append(entry)
elif ai_date <= created < ai_date + window:
after_prs.append(entry)
page += 1
if len(prs) < 100:
break
def stats(prs: list) -> dict:
if not prs:
return {"count": 0, "avg_size": 0, "weekly_rate": 0.0}
return {
"count": len(prs),
"avg_size": sum(p["size"] for p in prs) // len(prs),
"weekly_rate": round(len(prs) / 13, 1), # 90 天 ≈ 13 周
}
before = stats(before_prs)
after = stats(after_prs)
rate_change = (after["weekly_rate"] / max(before["weekly_rate"], 0.1) - 1) * 100
size_change = (after["avg_size"] / max(before["avg_size"], 1 ) - 1) * 100
return {
"before_ai": before,
"after_ai": after,
"velocity_change": f"{rate_change:+.0f}%",
"avg_pr_size_change": f"{size_change:+.0f}%",
# ⚠️ 如果速率提升 >50% 且平均 PR 体积也增大,是功能膨胀的强烈信号
"bloat_risk": rate_change > 50 and size_change > 20,
}
if __name__ == "__main__":
result = fetch_pr_velocity(
owner="your-org",
repo="your-product",
token="ghp_xxxx",
ai_adoption_date="2025-09-01",
)
print("=== AI 工具引入前后对比 ===")
print(f" Before: {result['before_ai']['weekly_rate']} PR/周 "
f"均摊 {result['before_ai']['avg_size']} 行变更")
print(f" After: {result['after_ai']['weekly_rate']} PR/週 "
f"均摊 {result['after_ai']['avg_size']} 行变更")
print(f" PR 速率变化: {result['velocity_change']}")
print(f" PR 体积变化: {result['avg_pr_size_change']}")
print(f" 🚨 功能膨胀风险: {'HIGH' if result['bloat_risk'] else 'LOW'}")
如果你的输出显示 功能膨胀风险: HIGH,说明你的团队确实在用 AI 的速度更快地堆砌代码,但并不意味着你在更快地创造用户价值——这是值得拉响警报的信号。
系统化功能下线:Feature Kill Decider
发现了候选”僵尸功能”,下一步是做下线决策。这通常卡在两个地方:一是没有量化标准(”感觉没人用”不够有力),二是利益相关方阻力(”这是某位 VP 的 pet feature”)。以下框架帮你把决策结构化:
# feature_kill_decider.py
# 系统化的功能下线决策框架,用数据代替直觉
from dataclasses import dataclass, field
from enum import Enum
from typing import List
class KillSignal(Enum):
ZOMBIE = "zombie" # 极少有人用
REDUNDANT = "redundant" # 被更好的方案替代
HIGH_COST = "high_cost" # 维护成本不成比例
STRATEGIC = "off_strategy"# 偏离核心产品战略
@dataclass
class KillCandidate:
name: str
adoption_rate: float # 30 天内用过的 DAU 占比
last_used_days_ago: int # 最后一次被核心用户使用距今天数
duplicate_coverage: float # 其他功能已覆盖的功能点比例 (0–1)
maintenance_hours_per_month: float # 每月维护耗时(小时)
on_core_strategy: bool # 是否符合当前产品核心战略
signals: List[KillSignal] = field(default_factory=list)
def __post_init__(self):
if self.adoption_rate < 0.05:
self.signals.append(KillSignal.ZOMBIE)
if self.duplicate_coverage > 0.75:
self.signals.append(KillSignal.REDUNDANT)
if self.maintenance_hours_per_month > 20:
self.signals.append(KillSignal.HIGH_COST)
if not self.on_core_strategy:
self.signals.append(KillSignal.STRATEGIC)
def kill_score(self) -> float:
"""
下线评分:分数越高,越应该下线。
>= 0.70 → 强烈建议下线
>= 0.50 → 召集产品会议评估
< 0.50 → 保留,进入观察期
"""
return (
(1 - self.adoption_rate) * 0.30 +
min(self.last_used_days_ago / 180, 1.0) * 0.20 +
self.duplicate_coverage * 0.25 +
min(self.maintenance_hours_per_month / 40, 1.0) * 0.15 +
(0 if self.on_core_strategy else 1) * 0.10
)
def verdict(self) -> str:
score = self.kill_score()
labels = [s.value for s in self.signals]
if score >= 0.70:
return f"🔴 强烈建议下线 (score={score:.2f}, signals={labels})"
elif score >= 0.50:
return f"🟡 产品会议评估 (score={score:.2f}, signals={labels})"
return f"🟢 保留/观察期 (score={score:.2f}, signals={labels})"
if __name__ == "__main__":
candidates = [
KillCandidate("导出为 Keynote", 0.02, 150, 0.95, 6, False),
KillCandidate("自定义通知声音", 0.01, 220, 0.98, 3, False),
KillCandidate("数据看板 v1 (旧版)", 0.18, 8, 0.70, 28, True),
KillCandidate("快捷键教学弹窗", 0.07, 60, 0.40, 4, True),
KillCandidate("团队日历集成", 0.33, 2, 0.20, 12, True),
]
print(f"\n{'功能名称':<22} {'采用率':>7} {'月维护':>7} {'决策'}")
print("─" * 90)
for c in candidates:
print(f"{c.name:<22} {c.adoption_rate:>6.0%} {c.maintenance_hours_per_month:>6}h {c.verdict()}")
示例输出:
功能名称 采用率 月维护 决策
──────────────────────────────────────────────────────────────────────────────────────
导出为 Keynote 2% 6h 🔴 强烈建议下线 (score=0.81, ...)
自定义通知声音 1% 3h 🔴 强烈建议下线 (score=0.84, ...)
数据看板 v1 (旧版) 18% 28h 🟡 产品会议评估 (score=0.61, ...)
快捷键教学弹窗 7% 4h 🟢 保留/观察期 (score=0.40, ...)
团队日历集成 33% 12h 🟢 保留/观察期 (score=0.23, ...)
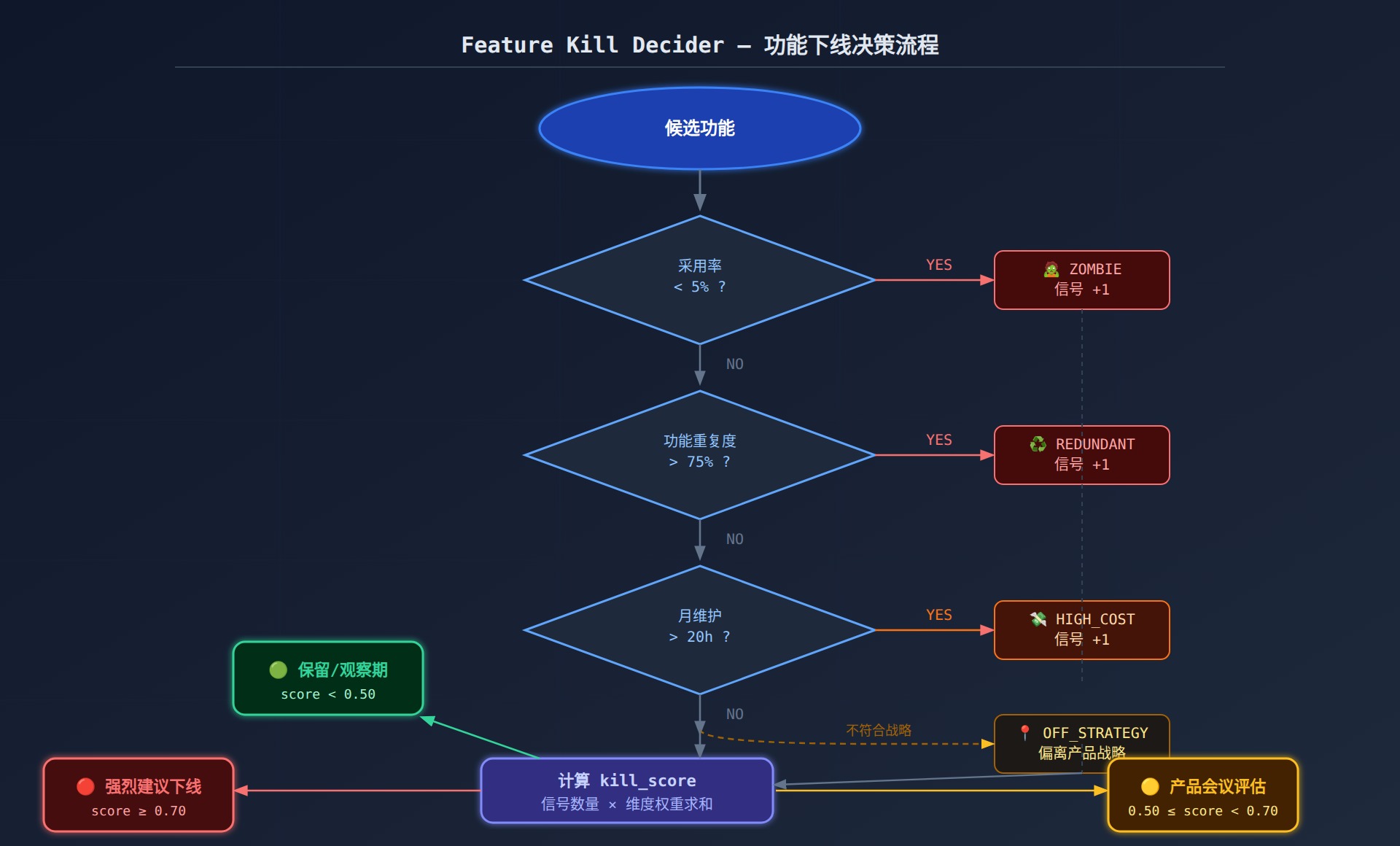
⚠️ 实操提醒:下线功能不等于”删除代码”,第一步是隐藏入口 + 内测通知,观察 30 天后再做最终决定。给真正有需求的用户预留反馈渠道,你会发现大多数时候反弹声音很小。
AI 时代的克制型产品开发流程
工具准备好了,但流程不变,数据就只是摆设。以下是一套可在团队落地的克制型开发流程:
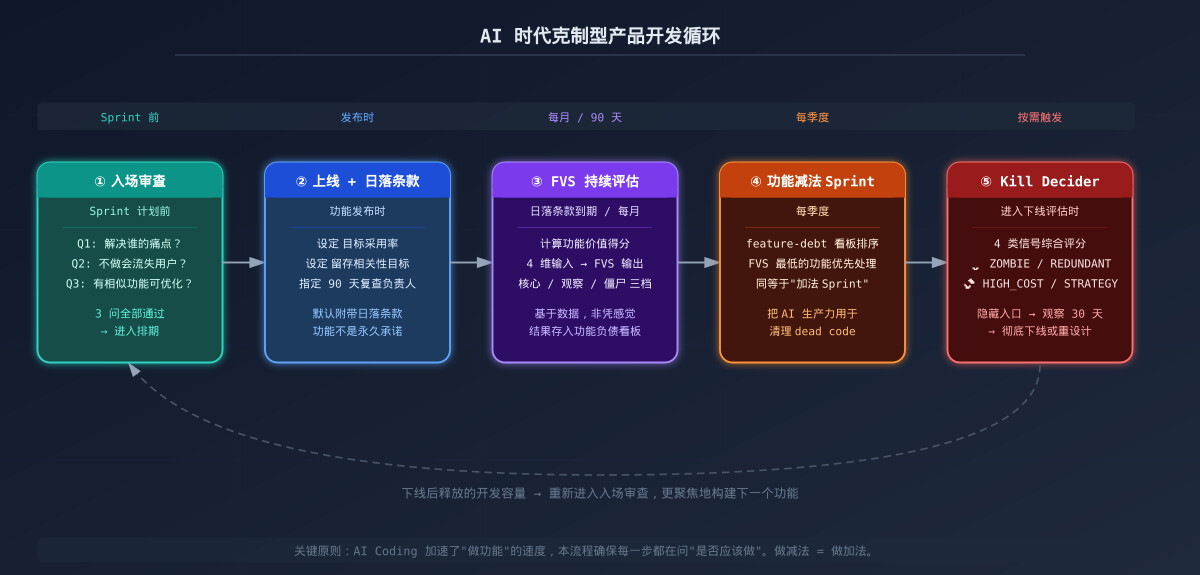
1. 在 Sprint 计划前做”功能入场审查”
每个新功能进入开发排期前,必须回答这三个问题:
① 这个功能要解决哪类用户的哪个具体痛点?(能命名真实用户则加分)
② 如果不做这个功能,用户会离开吗?还是仍然留存?
③ 现有功能中有没有 80% 相似的功能?如果有,为什么不优化它而是新建?
如果团队对第①题答不出具体用户画像,这个功能就不应该进排期。AI 可以在 2 小时内写完一个新功能,但不能替代这 5 分钟的思考。
2. 建立功能”日落条款”(Sunset Clause)
每个新功能在上线时,默认附带一个 90 天日落条款:
功能名称:___________
上线日期:___________
目标采用率:_____ %(90 天后)
目标留存相关性:_____
到期日复查负责人:___________
如未达标,自动进入下线评估流程。
这一条款的心理效果远大于技术效果:它让团队在做功能时就预设了”不是所有功能都应该永远存在”的意识。
3. 设置”功能负债看板”
技术债务(Technical Debt)已经是工程师的共识,但功能负债(Feature Debt)同样真实存在——每一个低价值功能都占用着:
维护带宽:Bug 修复、兼容性测试认知带宽:文档、客服、新员工培训产品专注度:让真正重要的功能淹没在噪音里
建议在 Jira / Linear 中新增一个 feature-debt 标签看板,每季度专门做一次”功能减法 Sprint”,用 FVS 分数排序,从最低分的功能开始处理。
4. 反直觉原则:把 AI 的生产力用于”做减法”
这是 AI 时代最被忽视的一条建议:用 AI Coding 来清理技术债务和废弃功能,而不只是增加新功能。
删除一段没人用的功能代码,和新增一段功能代码,需要的工作量差不多。但前者让产品更精准,后者却未必。用 AI 帮你:
- 自动识别 dead code(结合覆盖率工具)
- 重构老旧功能模块,降低维护成本
- 将分散的功能逻辑合并为统一的系统
- 编写测试,为下线功能提供安全网
对于已经在用 Codex 或 Claude Code 的团队,这一建议尤为紧迫:当你的 Agentic 工具能以分钟级速度生成功能时,你同样可以用它来以分钟级速度删除功能——给 Agent 一条指令:”找出过去 6 个月无访问日志的功能入口,生成下线 PR”,往往就能直接落地。做减法的成本,和做加法的成本,在 Agentic Coding 时代第一次真正平等了。
5. 学习”反例”:Basecamp/HEY 的产品克制
37signals(Basecamp 的母公司)是这个时代产品克制哲学最一致的践行者。他们的邮件产品 HEY 上线时有意删掉了”传统邮件用户认为必须有”的大量功能(文件夹分类、规则过滤、第三方集成),原则只有一个:只保留能让大多数用户体验更好的功能。
HEY 在 2024-2025 年的付费留存率远高于行业均值,证明这种克制是商业上可行的。
💡 核心洞察:Basecamp 联合创始人 Jason Fried 曾说过一句话值得所有产品经理贴在屏幕上:“Every feature is a promise you’ll have to keep.” 功能不是礼物,是承诺——承诺你会永远维护它、改善它、为它的 bug 负责。在 AI Coding 时代,这句话的分量只会更重,因为你做承诺的速度加快了 10 倍。
总结与行动清单
AI Coding 工具带来的研发效能提升是真实的,但它移除的是”构建速度”这个约束,而不是”构建什么”的判断力。当功能速度超越了产品思考速度,臃肿就成了必然结果——社区称之为 Slop 产品:每周都有新 changelog,但用户真正用到的功能从未增加,留存曲线悄然向下。
进入 Agentic Coding 时代,这一矛盾被进一步放大。以 OpenAI Codex 和 Claude Code 为代表的工具,已经能够从一句话需求到合并 PR 全程自主完成。它们是目前最火爆的编码工具,也是功能膨胀风险最高的加速器——因为它们让”先做了再说”的门槛降到了历史最低点。
解法不是放弃 AI,而是用数据和流程来补偿失去的那个制动器——在功能进来之前审查它,在功能上线之后持续评估它,在功能不再有价值时果断下线它。
你现在可以做的:
- 本周:在你的产品中跑一遍 FVS 计算,找出采用率 < 10% 的功能,这就是你的”功能减法清单”
- 下个 Sprint:给新功能默认加上 90 天日落条款,让”下线评估”成为默认流程
- 下个季度:安排一次”功能减法 Sprint”,用 Feature Kill Decider 系统处理积压的低价值功能
- 持续:监控 PR 速率与产品关键指标(DAU、留存率、NPS)的比值,当 PR 速率增长明显快于用户指标时,及时拉响警报
- 文化层面:在团队内传播”每个功能都是一个承诺”的意识,让做减法和做加法一样值得被鼓励
好产品从来不是功能最多的产品,而是在正确的地方做了正确的事的产品。
References
- Faros AI: 2026 Engineering Intelligence Report
- Pendo: The 2019 Feature Adoption Report
- Standish Group CHAOS Report: Feature Usage Statistics
- Faros AI: The 2026 Productivity Paradox of AI Coding
- Basecamp / 37signals Product Philosophy
- Second Talent: 84% of Developers Use AI Tools. Productivity Gains Are Only 10%.
- OpenAI Codex: Introducing Codex — an AI Coding Agent
- Anthropic Claude Code: Build software with Claude


 一分钟读论文:《AI 正在让开源协议失去约束力》
一分钟读论文:《AI 正在让开源协议失去约束力》