斯坦福大学的论文《同等预算下,单智能体为何胜过多智能体?》,在推理token预算严格相等的前提下,发现单智能体LLM系统在多跳推理任务上匹配或超越多智能体系统,为多智能体架构的效率优势提供了信息论层面的质疑。
信息论视角的理论基础
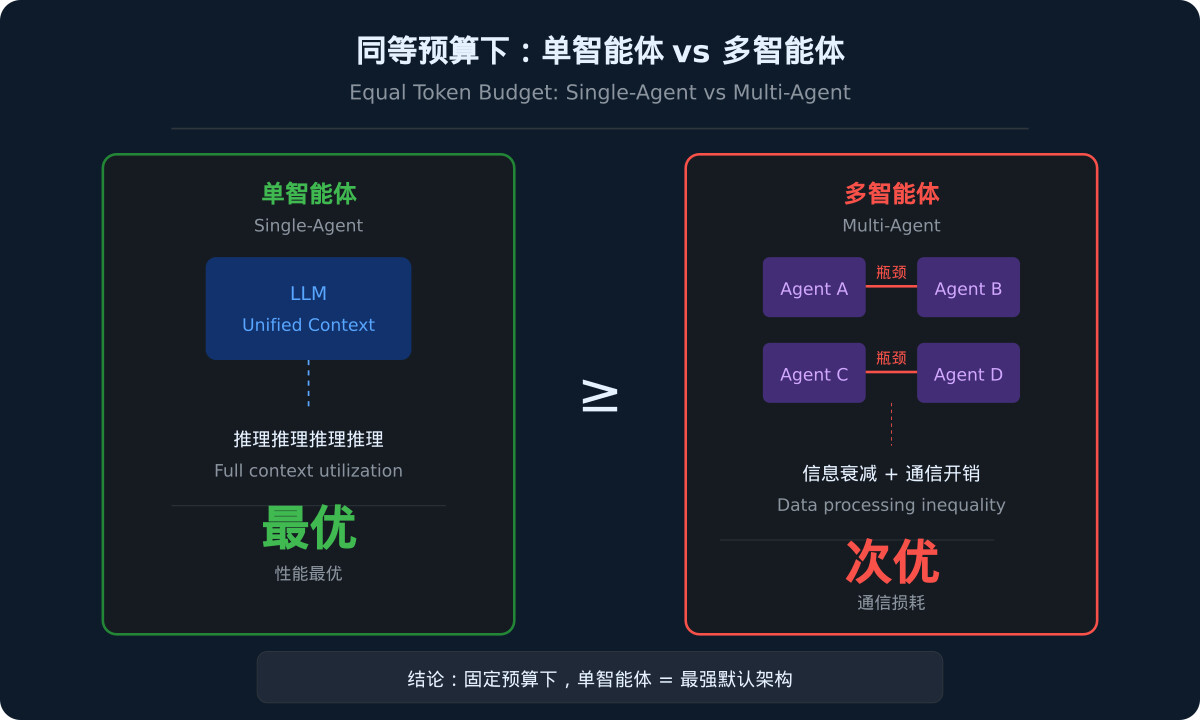
论文从数据处理不等式出发,建立了单智能体与多智能体系统在固定推理token预算下的理论对比框架。核心论点是:在完美利用上下文的前提下,单智能体系统是信息效率更高的架构。
多智能体系统在执行过程中涉及多个agent之间的通信和协调,每一次信息传递都引入了额外的信息瓶颈。根据数据处理不等式,信息在通过一系列处理步骤后不会增加,而多智能体系统中的通信环节增加了信息处理的链条长度,导致信息损耗。相比之下,单智能体系统在统一上下文内部进行推理,避免了跨agent的信息衰减。
实验设计与核心结果
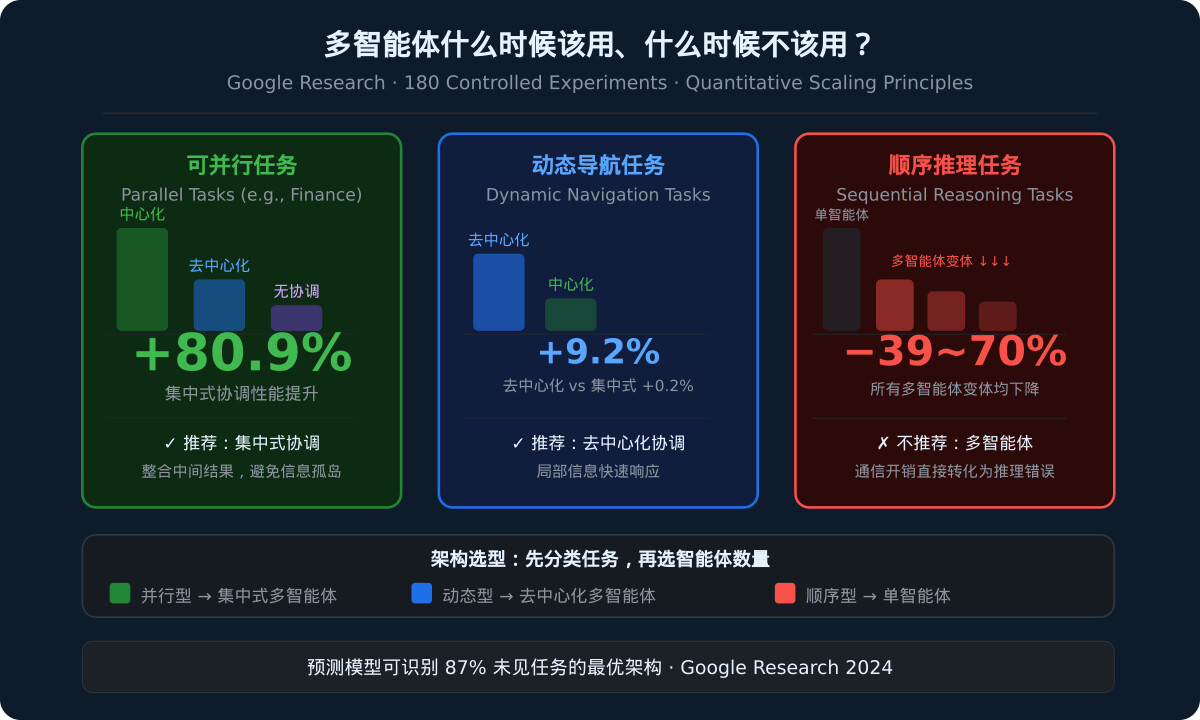
论文在三个模型系列(Qwen3-30B-A3B、DeepSeek-R1-Distill-Llama-70B、Gemini-2.5)和两个多跳推理数据集(FRAMES、MuSiQue)上进行了对比实验,涵盖五种多智能体架构。
核心发现是:在推理token预算匹配的前提下,单智能体系统是最强的默认架构。跨模型系列和数据集,单智能体在所有预算条件下都是性能最优或与最优系统统计上无显著差异。此外,单智能体在达成相同或更好结果的同时,消耗的推理token远少于任何多智能体变体。
上下文退化实验
论文通过四种上下文退化方式验证了理论预测的边界条件。实验结果显示了一个清晰的临界点:在轻度退化时,单智能体仍然领先;在重度退化(如掩码比例达到0.7)时,多智能体系统开始反超。这一结果验证了理论预测——当单智能体的有效上下文利用率下降到一定程度后,结构化多步推理才展现出对退化的鲁棒性。
评估方法论的诊断
论文还揭示了两个重要的评估 artifact。首先是API层面的预算控制存在偏差,特别是Gemini-2.5的thinking token计数机制可能扭曲实际消耗的计算量。其次是基准测试对改写敏感,部分多智能体系统的优势可能源于对特定问题表述的过拟合,而非真正的推理能力提升。
这些发现表明,许多被报告的多智能体系统优势,可能更好地由未计量的计算和上下文效应来解释,而非内在的架构优势。


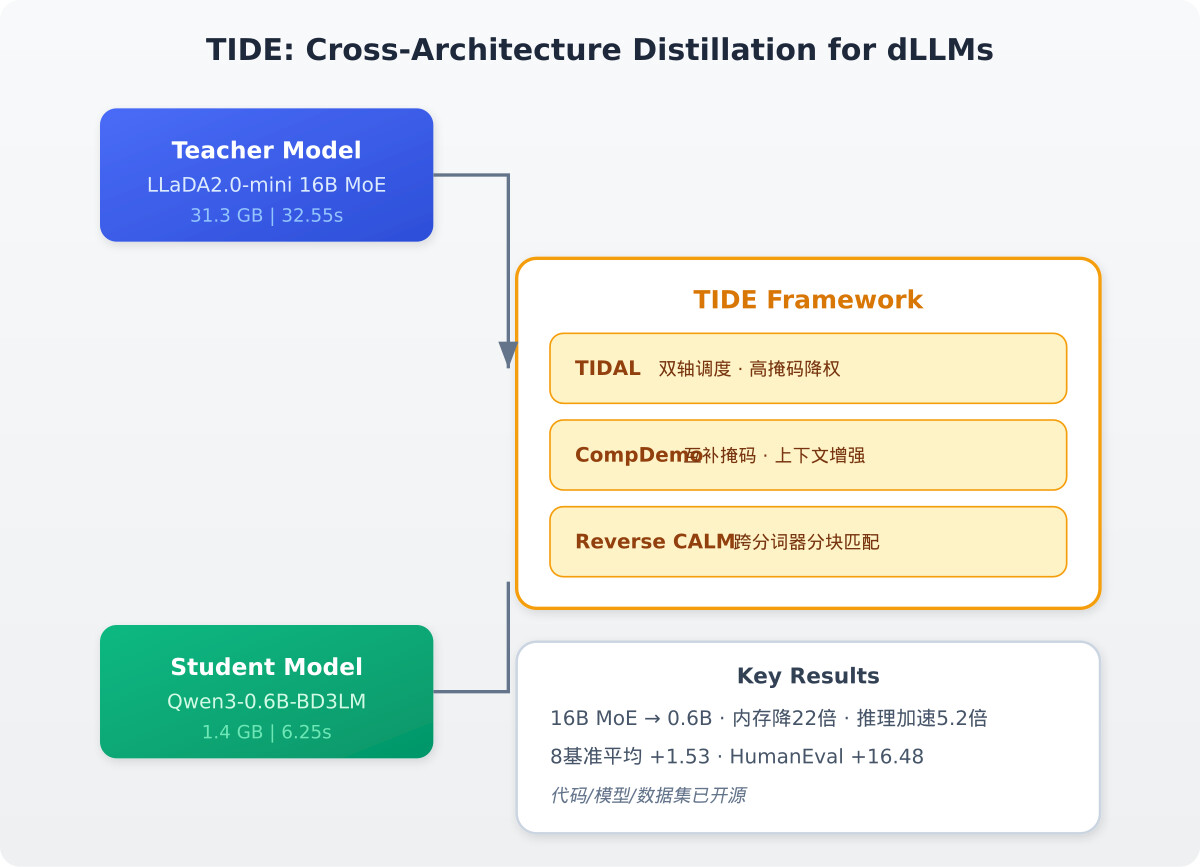 一分钟读论文:《把百亿模型装进手机:TIDE实现扩散语言模型跨架构蒸馏》
一分钟读论文:《把百亿模型装进手机:TIDE实现扩散语言模型跨架构蒸馏》