Cornell 大学 Prince Zizhuang Wang 和 Shuli Jiang 的论文《PRIME: Training Free Proactive Reasoning via Iterative Memory Evolution for User-Centric Agent》,提出了一种梯度自由的学习框架,通过显式经验积累而非参数优化实现 Agent 的持续进化。该框架将多轮交互轨迹蒸馏为三语义区的结构化经验,在多个用户中心环境中达到与基于梯度方法相当的性能。
梯度学习的局限性
基于强化学习的 Agent 训练方法面临三个核心挑战。训练成本过高——强化学习需要大量交互数据来收敛,每次训练需要 GPU 集群数天甚至数周的计算。信用分配困难——在多轮 Agent-用户交互中,哪一步做对了、哪一步做错了,很难归因。用户可能在一轮对话中提出模糊需求,Agent 通过多轮澄清才完成任务,这种长程依赖让梯度信号变得模糊。可解释性缺失——模型参数是黑箱,很难说清楚 Agent 为什么做出某个决策,这对需要审计和调试的工业场景是问题。
PRIME 框架的核心设计
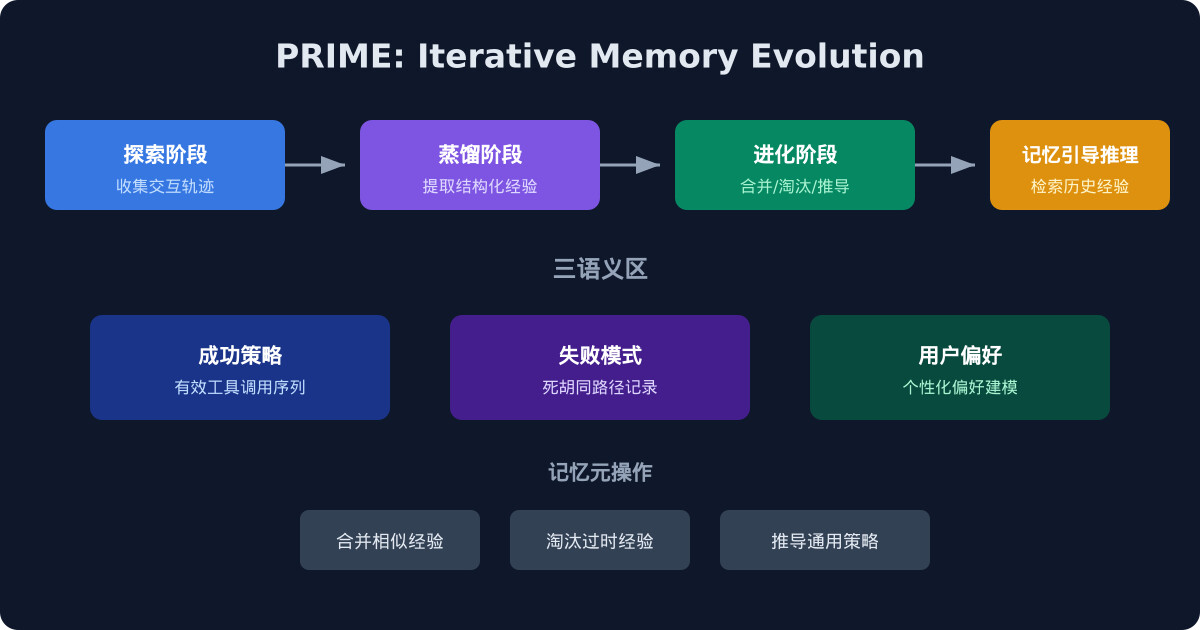
PRIME 的基本假设是 Agent 的学习不应该发生在参数空间里,而应该发生在记忆空间里。该框架将 Agent 从每次用户交互中提炼出三类结构化经验:成功策略——哪些工具调用序列有效,哪些提示词模板能准确理解用户意图。失败模式——哪些路径走进了死胡同,哪些工具组合会产生冲突。用户偏好——这个用户更喜欢简洁还是详细的回答,对哪个领域有专业知识。
PRIME 的流水线分为四个阶段。探索阶段收集 Agent 在与用户的多轮对话中的完整交互轨迹,包括用户的初始请求、Agent 的每次推理和工具调用、用户的反馈以及最终结果。蒸馏阶段自动分析交互轨迹,提取结构化经验并归入三个语义区,包括模式识别、因果分析和泛化。进化阶段对记忆库执行三种元操作——合并相似经验、淘汰过时经验、从多条经验中推导出新的通用策略。记忆引导推理阶段在新任务中检索相关的历史经验,通过语义相似度、时间相关性以及用户匹配度进行多维度的经验检索。
实验结果与外化框架的关联
PRIME 在多个用户中心环境中进行了实验,包括客服对话、任务规划和个人助手场景。主要发现:性能可竞争——在多个基准上,PRIME 达到了与基于梯度的方法相当的性能水平,考虑到 PRIME 不需要任何模型微调,这个结果相当显著。成本优势——由于不需要 GPU 训练,PRIME 的运行成本远低于 RL 方法。可解释性提升——结构化经验让 Agent 的决策过程变得透明,当 Agent 做出某个选择时,可以追溯到具体的历史经验。持续改进——随着交互轮数增加,PRIME Agent 的性能持续提升,没有观察到明显的饱和点。
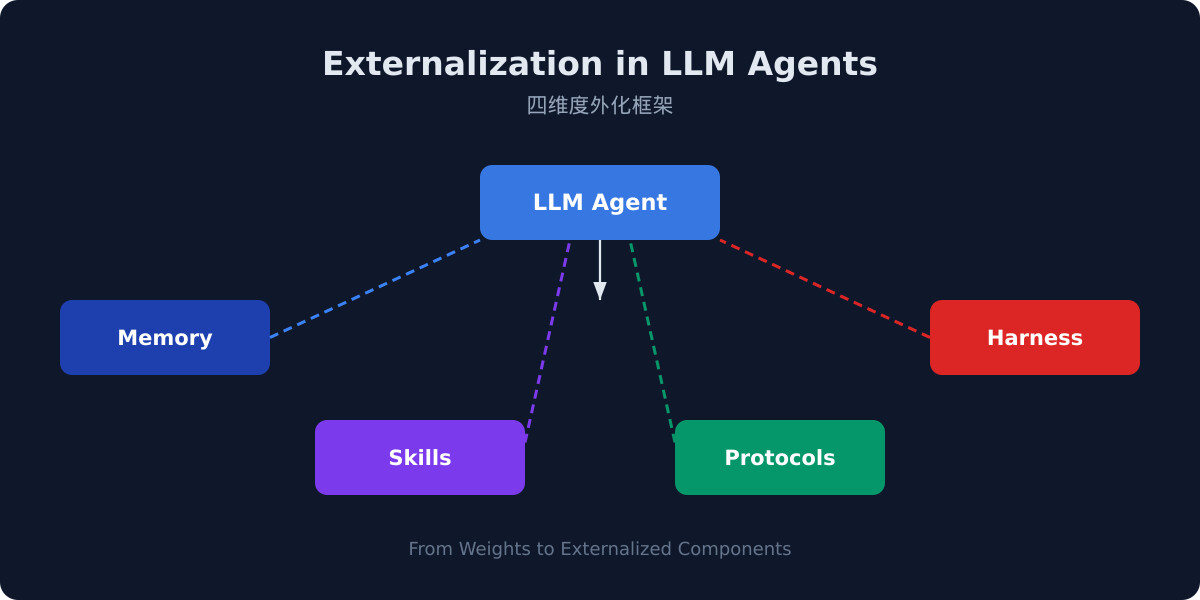
在第 30 篇 LLM Agent 外化设计范式中,作者提出了 Memory、Skills、Protocols 和 Harness 四个维度的框架。PRIME 恰好聚焦于 Memory 维度的具体实现。外化框架提出了记忆应该作为独立组件的宏观理念,而 PRIME 回答了记忆如何被高效组织和进化这个微观问题。
PRIME 目前也有几个明显的局限:经验提取的质量依赖蒸馏算法,自动提取的经验是否准确取决于蒸馏模块的设计;长期记忆管理随着交互轮数增加,记忆库的规模会快速增长;跨用户泛化当前经验主要服务于单个用户,如何构建跨用户的共享知识库同时保护隐私是开放问题。


 一分钟读论文:《LLM Agent 的外化设计范式》
一分钟读论文:《LLM Agent 的外化设计范式》