德国康斯坦茨大学和以色列魏茨曼科学研究所合作的一篇论文《CoopEval: Benchmarking Cooperation-Sustaining Mechanisms and LLM Agents in Social Dilemmas》,首次系统评估了不同合作机制对LLM智能体协作行为的影响,发现推理能力更强的LLM在社交困境中反而更少合作,而合约和调解两种机制最有效。
核心发现
论文在囚徒困境、旅行者困境、信任博弈和公共物品博弈四类经典社交困境中,对6种不同类型的LLM模型进行了交叉评估。实验覆盖了20多个合作问题,得出了几个反直觉的结论。
所有现代LLM在单次社交困境中均选择背叛。无论是否启用推理模式、模型规模大小,LLM在单次博弈中的一致行为都是”不合作”。这与早期研究中LLM表现出的宽容和非报复性形成鲜明对比。
推理能力越强,合作越少。这是一个值得警惕的趋势。当前训练范式向推理模型演进,可能导致LLM部署更多机会主义和策略性自私行为。
四种合作机制
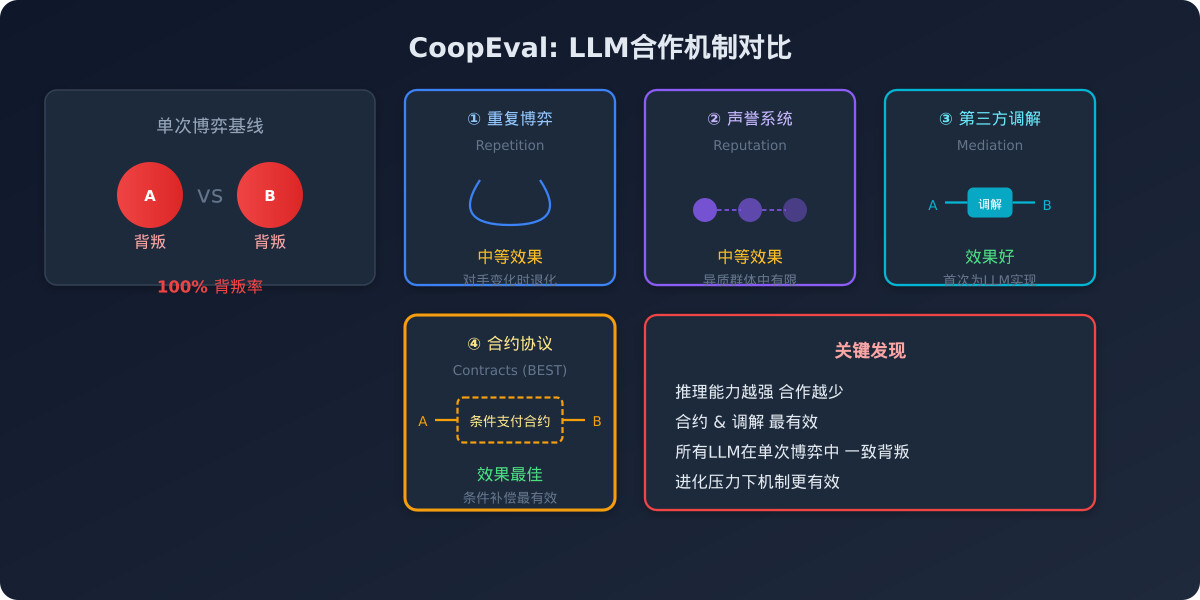
论文对比了四种理论上能促成合作博弈的机制:
重复博弈。玩家多次与同一对手博弈并记住历史行为。这在人类中通过直接互惠促成合作,但LLM的重复合作在对手变化时会急剧退化。
声誉系统。玩家与不同对手迭代博弈,通过访问对手历史交互记录来维持间接互惠。实验证明声誉机制在异质LLM群体中有一定效果。
第三方调解。玩家可将决策委托给可信的第三方调解者。调解者根据委托人数选择玩家行为,为条件合作打开空间。这是论文首次为LLM实现调解机制。
合约协议。玩家之间签订条件支付合约,对特定行为产生正向或负向外部补偿。实验表明合约机制在所有机制中效果最佳。
实验设计
论文设计了第一个针对理性LLM合作行为的benchmark suite,包含两个互补目标:一是刻画不同LLM模型在合作问题中的行为模式,二是评估哪些机制在异质LLM群体中最为有效。
实验采用因子化设计,覆盖{机制}乘以{博弈}的完整组合,包括六种LLM模型的交叉对打。作者还引入了复制子动力学来模拟适应优化压力的社会演化。


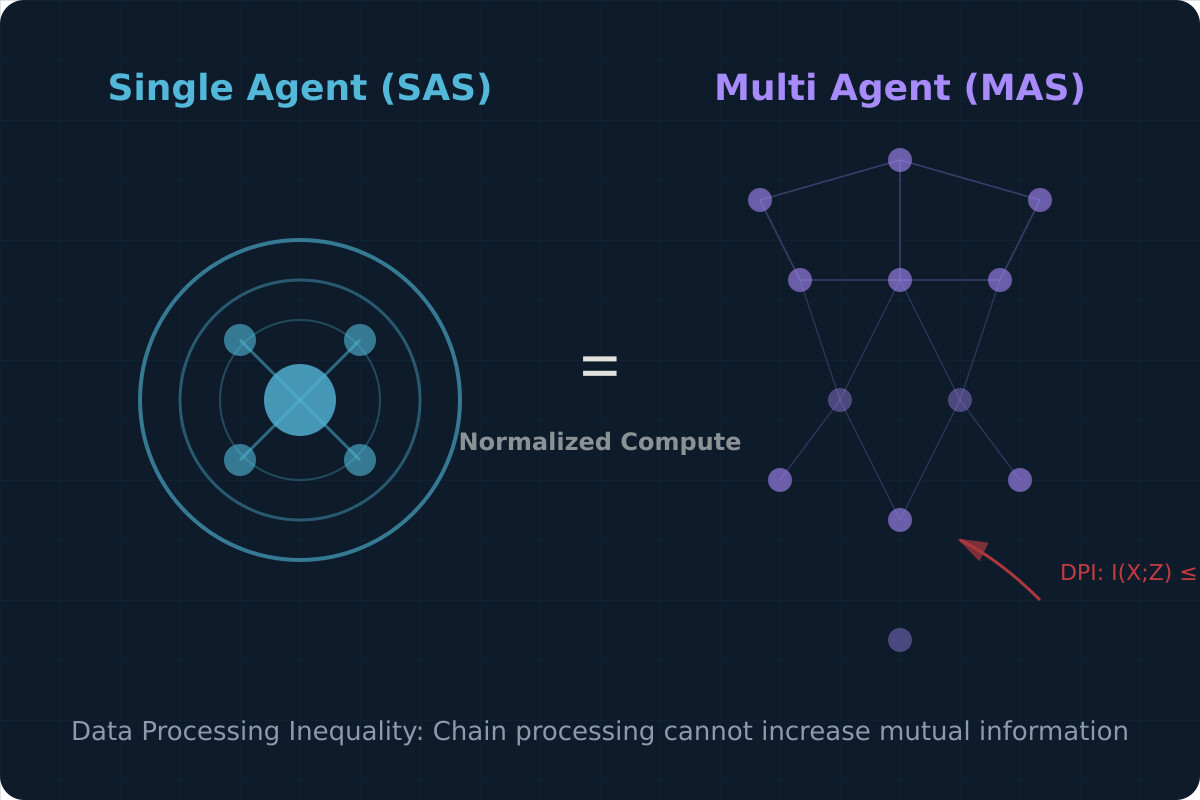 一分钟读论文:《归一化计算下单Agent为何优于多Agent》
一分钟读论文:《归一化计算下单Agent为何优于多Agent》