Google Research用180组受控实验揭示了一个反直觉结论:多智能体协作在顺序推理任务上会导致39-70%的性能下降,而非提升。如果你的团队正在盲目堆智能体,建议你先读这篇。
核心发现:多智能体不是银弹
论文对180种智能体配置进行了系统评估,提出了首个AI智能体系统的量化缩放原则。核心结论是:多智能体协作的效果高度依赖任务类型,不存在”越多越好”的通用规律。
有几个数据值得注意:
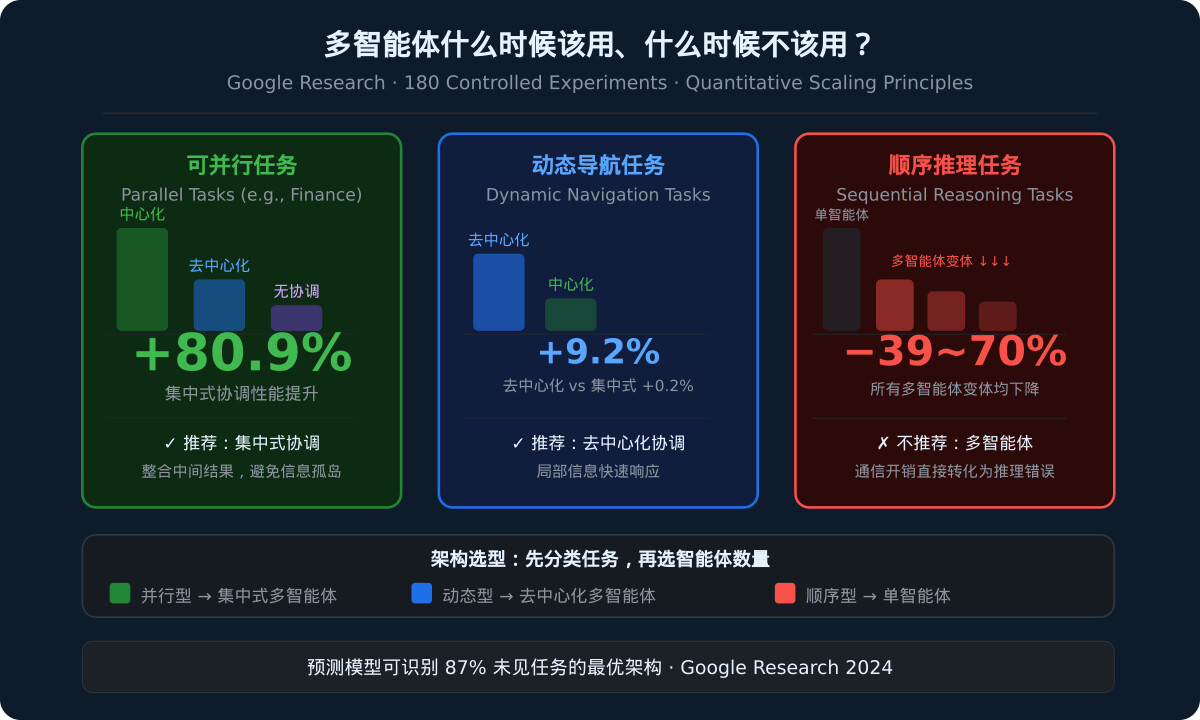
- 在可并行任务(如金融推理)上,集中式协调架构可以提升
80.9%的性能。 - 在动态网页导航任务上,去中心化协调优于集中式(
+9.2%vs+0.2%)。 - 在顺序推理任务上,所有多智能体变体导致
39-70%的性能下降——这不是”稍差一点”,而是”悬崖式下降”。 - 论文引入的预测模型可以识别
87%未见任务的最优架构。
研究框架:180组实验怎么做的
论文构建了系统化的评估框架,覆盖了三个关键维度:
架构类型: 集中式协调、去中心化协调、无协调、混合架构等多种变体。
任务类型: 从可并行的金融推理,到需要严格顺序的推理任务,再到动态环境中的网页导航。
缩放变量: 智能体数量、通信模式、信息流结构等参数的系统变化。
这种受控实验设计的关键优势在于,它隔离了”协调增益”与”信息访问增益”的混淆——这是之前大多数多智能体比较研究无法做到的。
架构-任务对齐:比智能体数量更重要的因素
论文最重要的贡献是提出了”架构-任务对齐”(architecture-task alignment)的概念。研究发现:
- 可并行任务需要集中式协调来整合中间结果,避免信息孤岛。
- 动态导航任务需要去中心化协调,让每个智能体根据局部信息快速响应。
- 顺序推理任务根本不需要多智能体——每个智能体的输出成为下一个的输入,通信开销直接转化为推理错误。
这个结论对实际工程有直接指导意义:在考虑引入多智能体之前,先回答一个问题——你的任务真的适合多智能体吗?
预测模型:给架构选型一个数据驱动的答案
论文还提出了一种预测模型,输入任务的特征(可并行性、复杂度、动态性),输出最优架构类型。在留一法交叉验证中,该模型对未见任务的架构选择准确率达到87%。
这意味着,多智能体架构选型不再完全依赖直觉和试错,而是可以基于任务特征进行量化预测。
实践建议
基于这篇论文的研究结论,给出以下建议:
- 先做任务分类。 在引入多智能体之前,先判断你的任务属于并行型、动态型还是顺序型。顺序型任务直接排除多智能体。
- 用预测模型辅助决策。 论文提供的预测框架可以直接用于新任务的架构选型。
- 关注协调层设计。 如果确需多智能体,协调层设计应被视为与模型选择同等重要的架构决策,而非事后补充。
- 警惕”智能体越多越好”的叙事。 这篇论文用180组实验证明,在顺序推理场景下,多智能体不仅是效率问题,更是正确性问题。
与后续研究的关联
这篇Google缩放论文揭示了”什么时候不该用多智能体”,而同期发表的协调层论文[arXiv 2605.03310]则回答了”怎么设计协调层”。两篇论文共同指向一个结论:多智能体系统的核心挑战不是模型能力,而是架构设计。
对于正在构建多智能体系统的团队来说,这篇论文的价值在于——它给了你一个停止盲目堆智能体的理由,同时提供了一套数据驱动的架构选型方法。


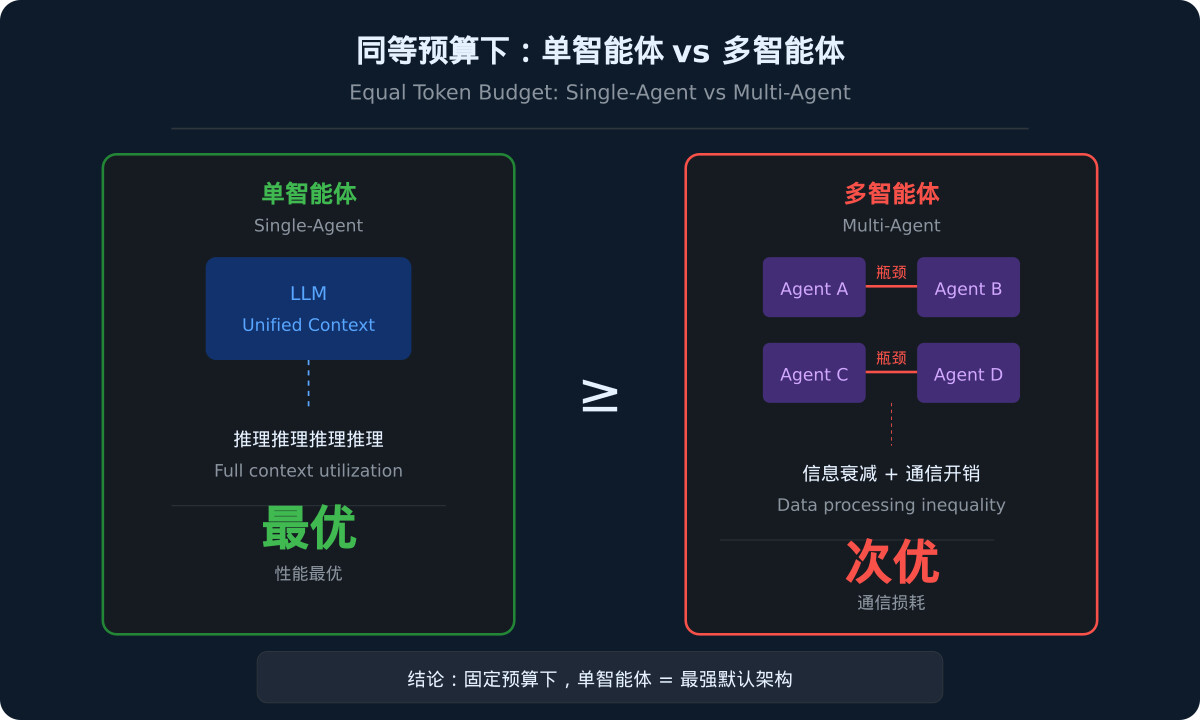 一分钟读论文:《同等预算下,单智能体为何胜过多智能体?》
一分钟读论文:《同等预算下,单智能体为何胜过多智能体?》