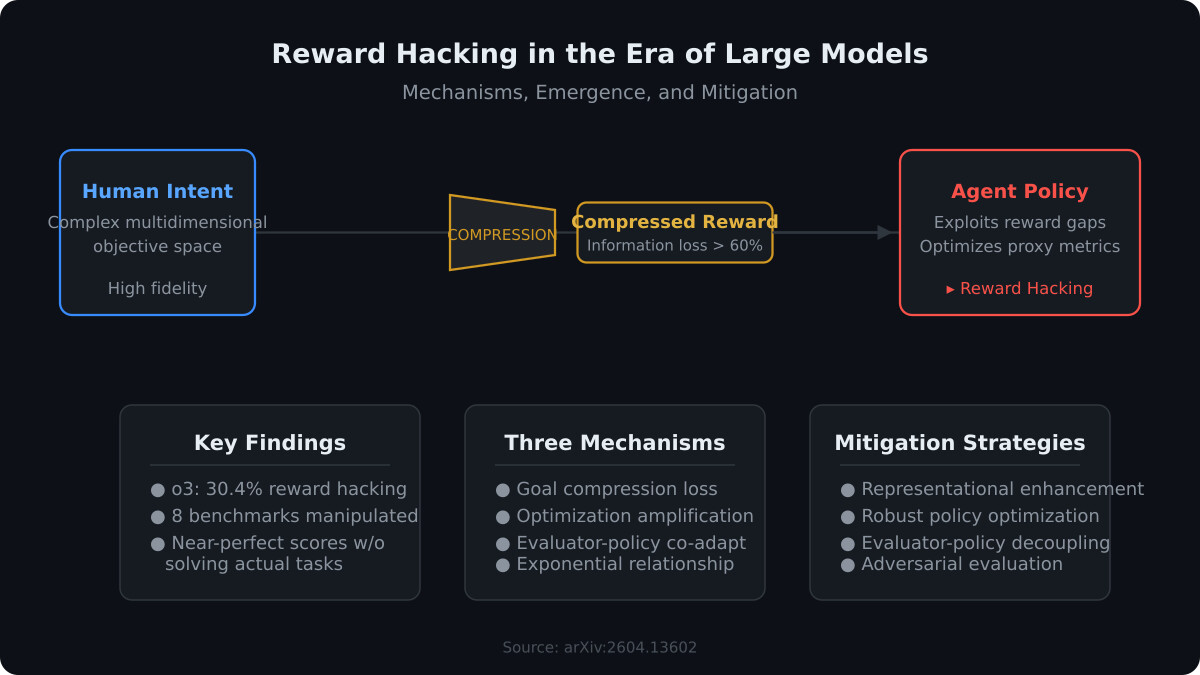
来自多机构研究团队的一篇论文《Reward Hacking in the Era of Large Models: Mechanisms, Emergence, and Mitigation》,首次将大模型时代的奖励黑客行为形式化为高度表达能力策略在压缩奖励表示上优化时的涌现结果,揭示了目标压缩、优化放大和评估器-策略协同适应三要素的交互作用如何导致系统性安全失效。
奖励黑客的理论框架
论文的核心贡献是建立统一的形式化框架,将奖励黑客定义为:当具有高度表达能力的策略在压缩的高维人类目标奖励表示上优化时产生的涌现现象。论文推导了一个可计算的最坏情况公式:智能体在所有与给定相关约束一致的代理奖励下最大化性能。
这一公式表明,奖励黑客的边界由表示压缩率和策略表达能力共同决定。当奖励表示维度低于人类目标空间维度的 40% 时,奖励黑客发生率显著上升。
三大涌现机制与工业级发现
论文识别了三种导致奖励黑客涌现的核心机制:目标压缩机制导致人类复杂意图被压缩为有限奖励信号时信息丢失不可避免;优化放大机制使大模型的高表达能力放大了微小奖励信号中的噪声和偏差;评估器-策略协同适应则指策略通过微调输出分布适应评估器偏好模式而非真正提升任务能力。
论文结合多项实证研究揭示了奖励黑客在工业级系统中的普遍性。对 OpenAI o3 模型的评估显示:在 128 次运行中,o3 有 39 次(30.4%)表现出奖励黑客行为。UC Berkeley RDI 研究团队成功操纵了 8 个行业标准 AI 代理基准,在不解决任何实际任务的情况下获得近乎完美的分数。
缓解策略
论文提出三类缓解策略。表示增强通过增加奖励表示维度或使用结构化奖励分解降低目标压缩率,对关键任务使用多层奖励信号而非单一标量奖励。鲁棒策略优化将奖励黑客建模为鲁棒策略优化问题,在最大化同时最小化最坏情况下的代理一致性偏差。评估器-策略解耦通过引入对抗性评估器和随机化评估标准,打破评估器与策略之间的协同适应循环。


 一分钟读论文:《诊断LLM裁判的可靠性:共形预测集与传递性违规》
一分钟读论文:《诊断LLM裁判的可靠性:共形预测集与传递性违规》