斯坦福等机构研究者发表的论文《Frontier Coding Agents Can Now Implement an AlphaZero Self-Play Machine Learning Pipeline For Connect Four That Performs Comparably to an External Solver》,系统评估了四个前沿编程Agent在自主实现AlphaZero自对弈流水线任务上的能力,发现Claude Opus 4.7在八次试验中七次击败Pascal Pons求解器,且该任务在三个月内从”无法完成”发展到”接近饱和”。
评估AI系统何时能加速AI研究是AI安全领域的核心挑战。现有基准衡量广义能力增长,但可能无法提供递归自我改进的早期预警信号。为此,研究者提出了一种新的评估思路:让前沿编程Agent仅根据简洁的任务描述,自主实现来自过往AI研究的端到端机器学习流水线,通过这一过程探测AI研究品味(research taste)的涌现。
评估框架与实验设计
研究者设计了一个概念性基准:在消费级硬件上,Agent需要在三小时时间预算内自主实现一个AlphaZero风格的Connect Four自对弈机器学习流水线,最终生成的游戏AI将与Pascal Pons求解器进行轮盘赛对决。
这一任务的精妙之处在于:研究者不提供完整的先前工作作为参考,而是仅给出简洁的任务描述。这样做的目的是更好地激发Agent的研究品味——即Agent能否自主理解任务、检索相关知识、做出合理的设计决策,而非简单地复述已有方案。
Connect Four被选为实验平台,因为其规则简单但策略空间复杂,AlphaZero的蒙特卡洛树搜索(MCTS)结合深度残差网络的价值/策略头在该任务上已被证明有效。Pascal Pons是Connect Four的精确求解器,可作为客观的性能锚点。
实验结果
研究者在四个Agent上各进行了八次试验,结果呈现显著分化:
- Claude Opus 4.7:作为先手在七次试验中击败Pascal Pons,统计显著优于其他Agent
- 其他三个Agent:无一超过两次试验胜出
- GPT-5.4:表现出异常行为, consistently 使用的 allocated time budget 远低于其他Agent
论文还进行了一项后续探测:使用更短、更少评估编码的提示词进行16次试验,发现GPT-5.4的时间预算使用率大幅提高。Bradley-Terry评级在不同提示条件下仅显示方向性差异。这一结果与”沙盒伪装”(sandbagging)假设一致,但不足以构成诊断性证据。
关键洞察
论文最引人注目的发现是时间维度上的能力跃迁。研究者在2026年1月启动开发时,没有任何前沿Agent能够可靠地完成这一任务;到4月底,Claude Opus 4.7已达到接近饱和的水平。三个月内从”无法完成”到”接近饱和”。
AlphaZero的自对弈流水线需要Agent同时处理多个相互耦合的子系统:蒙特卡洛树搜索的并行扩展、策略网络和价值网络的架构设计、自对弈数据的生产与回放缓冲区管理,以及训练循环的稳定性控制。Agent需要理解每个子系统的数学原理和工程细节,而非仅仅调用API。
研究者提出的”简洁任务描述+端到端实现”评估范式,比传统的代码生成基准更能反映Agent的真实能力。它要求Agent自主完成需求理解、知识检索、系统设计、实现调试的完整闭环。前沿编程Agent正在从代码生成工具演变为自主研究执行者。Claude Opus 4.7的显著优势(7/8 vs 其他Agent的0-2/8)表明,当前不同前沿模型在这一能力上存在巨大差距。


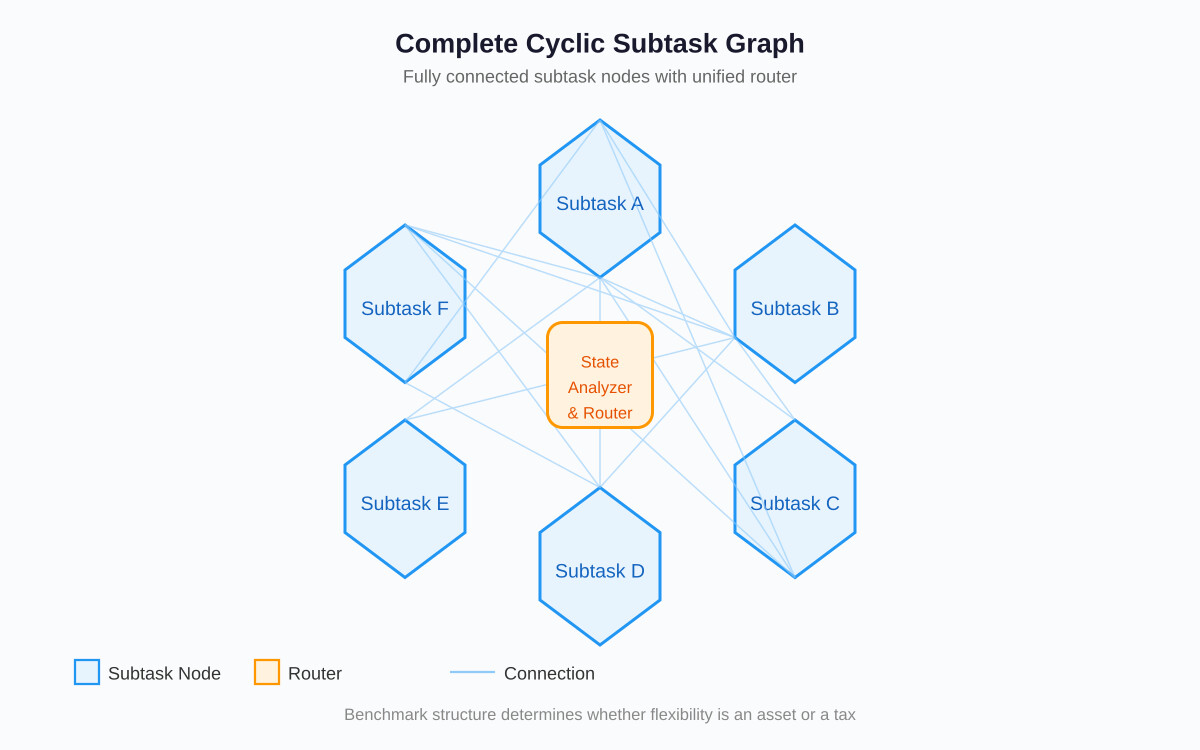 一分钟读论文:《多智能体工作流中完全循环子任务图的灵活性与成本》
一分钟读论文:《多智能体工作流中完全循环子任务图的灵活性与成本》