今天的 AI Agent 大多能在 10–20 步内完成一个明确的小任务。但现实世界里最有价值的工作从来不是这样的:修复一个生产级 Bug 需要读代码、复现、定位、打补丁、写测试、验证——不止 7 步,而是几十步;一套完整的数据处理流水线可能跨越数十个工具调用;安全审计任务需要跨阶段协作,中途任何一步失败都可能让整个流程作废。这类任务统称 Long Horizon Task,而能够稳定完成它们的系统,就是 Long Horizon Agent。
TerminalBench-2 的公开数据可以直观感受到差距:在 89 个真实长任务上,最好的单 Agent 系统(GPT-5.5)也只有 82% 的成功率,基准 ReAct 模式只有 40%。这不是模型能力不足——而是架构不足。本文从端到端视角,拆解 Long Horizon Agent 的六层工程架构,给出每一层的核心设计决策。
目录
- Long Horizon 的本质挑战
- 六层全栈架构总览
- 第一层:分层规划与任务图
- 第二层:四维记忆系统
- 第三层:执行引擎与工具编排
- 第四层:状态持久化与断点续传
- 第五层:错误恢复与重规划
- 第六层:可观测性与成本控制
- 总结与行动清单
Long Horizon 的本质挑战
普通 Agent 任务是一个单点问题:给定输入,产出答案,任务结束。Long Horizon 任务是一个动态过程:目标在执行中可能被细化,工具调用的结果会影响后续决策,失败不是异常而是常态,整个系统需要在不确定的长路径上保持方向感。
具体来说,有三类核心矛盾:
矛盾一:上下文有限 vs 任务无限长
当任务超过 30–40 步,历史轨迹会把上下文窗口塞满。最朴素的解法——截断最旧的内容——会让 Agent 失去早期关键信息(比如最初的约束条件、第一步的报错信息)。研究表明,主动折叠(Context Folding)比被动截断的任务成功率高 23%。
矛盾二:局部最优 vs 全局目标
ReAct 模式让 Agent 每一步都”想当前最优动作”,但在长任务中,当前最优不等于全局最优。一个”快速绕过”的临时方案可能让后续步骤陷入死局。需要分层规划来在宏观层保持全局约束。
矛盾三:幂等性 vs 副作用
长任务中工具调用会产生真实副作用:文件被创建、数据库被写入、API 被调用。一旦崩溃重启,如果没有状态持久化,这些副作用要么需要重做(浪费成本)、要么无法重做(破坏环境)。
💡 这三个矛盾的解法——Context Folding、分层规划、状态持久化——构成了 Long Horizon Agent 工程的核心三角。
六层全栈架构总览
一个完整的 Long Horizon Agent 系统包含六个垂直分层,每一层解决一类特定问题:

| 层 | 职责 | 关键技术 |
|---|---|---|
| ① 任务接入 & 分层规划 | 解析目标,构建任务图 | HTN、LLM 规划、DAG |
| ② 四维记忆系统 | 管理跨步骤的信息存取 | 向量数据库、知识图谱、Context Folding |
| ③ 执行引擎 & 工具编排 | 调用工具,驱动步骤执行 | 工具路由、沙箱、并行调度 |
| ④ 状态持久化 & 断点续传 | 保存和恢复执行状态 | Event Sourcing、Checkpoint、Temporal |
| ⑤ 错误恢复 & 重规划 | 识别失败,调整策略 | 失败诊断、Replan-not-Retry |
| ⑥ 可观测性 & 成本控制 | 监控、告警、Token 预算 | OpenTelemetry、成本熔断 |
这六层不是简单的线性流水线——记忆层横跨所有步骤,状态层为执行层提供持久化后盾,恢复层在任何时刻都可能被触发。数据沿两条主线流动:执行主线(①→③)和反馈回路(⑥→⑤→②→①)。
第一层:分层规划与任务图
Long Horizon 任务的规划不能是一个平铺的步骤列表,必须是分层的:宏观阶段(Macro Goals)定义”做什么”,微观步骤(Micro Steps)定义”怎么做”。宏观目标在整个任务生命周期内相对稳定,微观步骤则随执行结果动态调整。
数据结构(伪代码)
STRUCT MicroStep
id: string
description: string
tool: string # bash | file_read | file_write | …
params: map<string, any>
depends_on: list<string> # 依赖的步骤 ID(DAG 边)
status: pending|running|done|failed
STRUCT MacroGoal
id: string
description: string
success_criterion: string # 可机器验证的完成条件
micro_steps: list<MicroStep>
status: pending|running|done|failed
STRUCT TaskGraph
task_id: string
original_goal: string
constraints: map # 时间限制、资源限制、禁止操作
macro_goals: list<MacroGoal>
current_macro() → MacroGoal # 返回第一个 pending/running 阶段
completion_ratio() → float # done 步骤数 / 全部步骤数
HTN 分解流程

⚠️ 关键设计点:
success_criterion字段是可机器验证的完成条件,而不是模糊的描述。例如”所有单元测试通过,覆盖率 ≥ 80%”而不是”代码修好了”。这是后续自动验收的基础。
第二层:四维记忆系统
人类完成复杂长任务靠的不只是短期记忆。Long Horizon Agent 同样需要四种不同粒度的记忆,各自解决不同问题:
| 记忆类型 | 存储什么 | 实现方式 | 生命周期 |
|---|---|---|---|
| 工作记忆 | 当前上下文(目标、最近动作、工具结果) | LLM 上下文窗口 + Context Folding | 步骤级 |
| 情节记忆 | 发生了什么(完整事件日志) | 向量数据库(带时间戳) | 任务级 |
| 语义记忆 | 领域知识(代码库结构、API 文档) | RAG(Qdrant / Chroma) | 持久化 |
| 程序记忆 | 怎么做(成功工具序列 / 解决方案模板) | 结构化技能库 | 持久化 |
统一记忆接口(伪代码)
INTERFACE LongHorizonMemory
# 工作记忆
add_to_working(role, content, metadata)
→ 缓冲区满 FOLD_THRESHOLD 条时触发 fold()
fold()
→ 用轻量 LLM 将缓冲区压缩追加到 context_summary
get_working_context() → string
→ "历史摘要 + 最近 5 条原文"
# 情节记忆
record_episode(event_type, content, outcome)
→ embed(content) → upsert 向量数据库
recall_similar(query, top_k) → list<episode>
→ embed(query) → cosine 检索
Context Folding 触发流程

💡 Context Folding vs 截断:截断是被动的——窗口满了就删最旧的。Folding 是主动的——在自然阶段边界时,用小模型把历史压缩成信息密度更高的摘要。这让 Agent 在第 80 步仍然”记得”第 3 步的关键约束。
第三层:执行引擎与工具编排
执行层负责将规划层的 MicroStep 转化为真实的工具调用,并处理调用结果。设计重点有两个:工具调用幂等性(允许安全重试)和结果归一化(让上层规划可以统一处理不同工具的输出)。
工具执行器(伪代码)
STRUCT ToolResult
success: bool
output: string # 截断至 4000 字符
error: string
metadata: map
PROCEDURE execute(step: MicroStep, dry_run: bool) → ToolResult
IF step.tool NOT IN registry
RETURN ToolResult(success=false, error="未知工具")
IF dry_run
RETURN ToolResult(success=true, output="[validated]")
TRY
RETURN registry[step.tool](step.params)
CATCH exception
RETURN ToolResult(success=false, error=exception.message)
基于拓扑序的并行调度

幂等性保障:
dry_run模式只验证参数,不产生副作用;失败后可安全重调同一MicroStep,不会重复写入。
第四层:状态持久化与断点续传
这一层是 Long Horizon Agent 区别于普通 Agent 的关键工程能力。一个跑了 40 步的任务,如果因为网络超时、机器重启或者模型 API 限流而中断,必须能从中断点恢复,而不是从头再来。
设计基于两个互补的模式:
- Checkpoint(阶段粒度):每完成一个宏观阶段,保存完整状态快照
- Event Sourcing(步骤粒度):每一步动作都作为事件写入日志,支持全量回放
检查点管理器(伪代码)
PROCEDURE save_checkpoint(task_graph, context_summary, step_index)
snapshot = {
step_index, saved_at,
context_summary,
task_graph: serialize(task_graph)
}
WRITE snapshot → "checkpoint_{step_index}.json"
PROCEDURE load_latest_checkpoint() → snapshot | null
files = SORTED glob("checkpoint_*.json")
IF files empty → RETURN null
RETURN PARSE(files.last)
PROCEDURE log_event(event_type, step_id, data, outcome)
event = {seq, timestamp, event_type, step_id, data, outcome}
APPEND event → "event_log.jsonl" # append-only,支持重放
带断点续传的主执行循环

第五层:错误恢复与重规划
失败在 Long Horizon 任务中不是异常,是必然。关键是如何有效地从失败中恢复。核心原则是:
Replan-not-Retry:如果连续同一策略失败超过阈值次数,不要继续重试,而是重新规划。
失败分类与恢复策略
ENUM FailureType
TOOL_ERROR # 工具调用本身出错
VALIDATION_FAIL # 结果不符合 success_criterion
TIMEOUT # 执行超时
BLOCKED # 连续无进展(步骤数超阈值)
TABLE RecoveryPolicies
FailureType max_retries default_action
TOOL_ERROR 2 retry
VALIDATION_FAIL 1 replan
TIMEOUT 1 rollback
BLOCKED 0 replan
错误恢复决策流程

⚠️ 重规划的”情节记忆”价值:重规划时检索类似历史失败,可以避免 LLM 提出”已知无效的方案”。这是程序记忆与情节记忆协同工作的典型场景。
第六层:可观测性与成本控制
Long Horizon Agent 如果没有可观测性,就是一个黑盒。一旦出问题,你不知道卡在哪一步、消耗了多少 Token、重规划了几次。生产级系统必须在每一步都有可度量的指标。
任务指标结构(伪代码)
STRUCT TaskMetrics
task_id, start_time
total_steps, successful_steps, failed_steps
replan_count
total_tokens, estimated_cost_usd
tool_call_counts: map<tool, int>
PROCEDURE record_llm_call(model, input_tokens, output_tokens)
total_tokens += input_tokens + output_tokens
estimated_cost_usd += tokens * model_price_per_1k
PROCEDURE check_budget(max_cost, max_steps) → (ok: bool, reason: string)
IF estimated_cost_usd > max_cost → RETURN (false, "成本超限")
IF total_steps > max_steps → RETURN (false, "步骤超限")
RETURN (true, "ok")
OpenTelemetry 集成与成本熔断

总结与行动清单
Long Horizon Agent 的工程挑战不在于”更聪明的模型”,而在于更完整的系统设计。六层架构的每一层都解决了真实的工程难题:分层规划防止目标漂移,四维记忆对抗上下文饱和,幂等执行让恢复成为可能,检查点保障了任务不因意外而从零开始,重规划让失败成为调整而不是终止,可观测性让整个过程从黑盒变成可控。
把这六层拼在一起,就是一个能稳定跑完”真实世界长任务”的 Agent 系统。
你现在可以做的:
- 先补检查点:如果你有现成的 Agent,先给它加上宏观阶段粒度的 Checkpoint——不需要重构整个架构,但立刻获得断点续传能力
- 引入 Context Folding:在执行循环里加入”每 N 步主动压缩一次历史”的逻辑,用轻量小模型做压缩,边际成本极低
- 实现 TaskMetrics:在每个工具调用点记录成本和步骤数,一旦发现成本异常上升,触发熔断而不是让任务无限跑
- 把”任务”从代码里分离出来:用类似本文
TaskGraph的结构来显式描述目标、约束和步骤,而不是把它们藏在提示词里——这是让系统可测试的基础 - 测量你的 Long Horizon 基准线:从 TerminalBench-2 选 10 个任务,跑一次,记录成功率和平均步骤数,作为优化的起点
References
- AgentFlow: Synthesizing Multi-Agent Harnesses for Vulnerability Discovery
- TerminalBench-2: Benchmarking Agents on Hard, Realistic Terminal Tasks
- AgentFold: Long-Horizon Web Agents with Proactive Context Folding
- Temporal.io: Durable Execution for Long-Running Workflows
- LangGraph: Building Stateful Multi-Actor Applications with LLMs


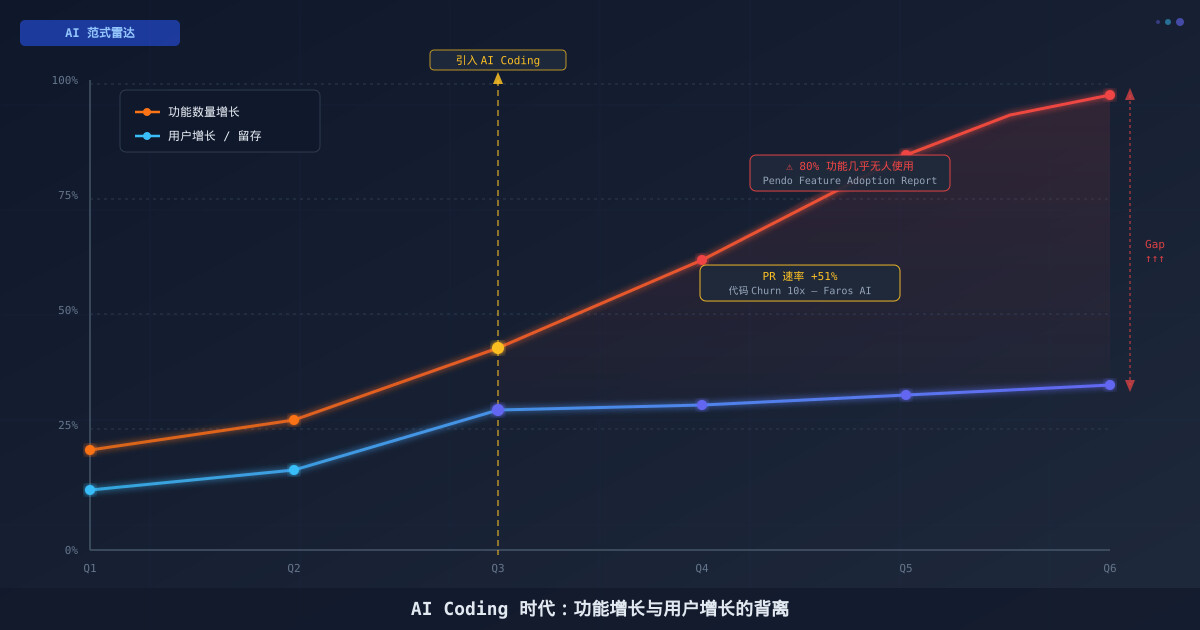 一分钟读论文:《AI Coding 时代,功能膨胀如何杀死好产品》
一分钟读论文:《AI Coding 时代,功能膨胀如何杀死好产品》