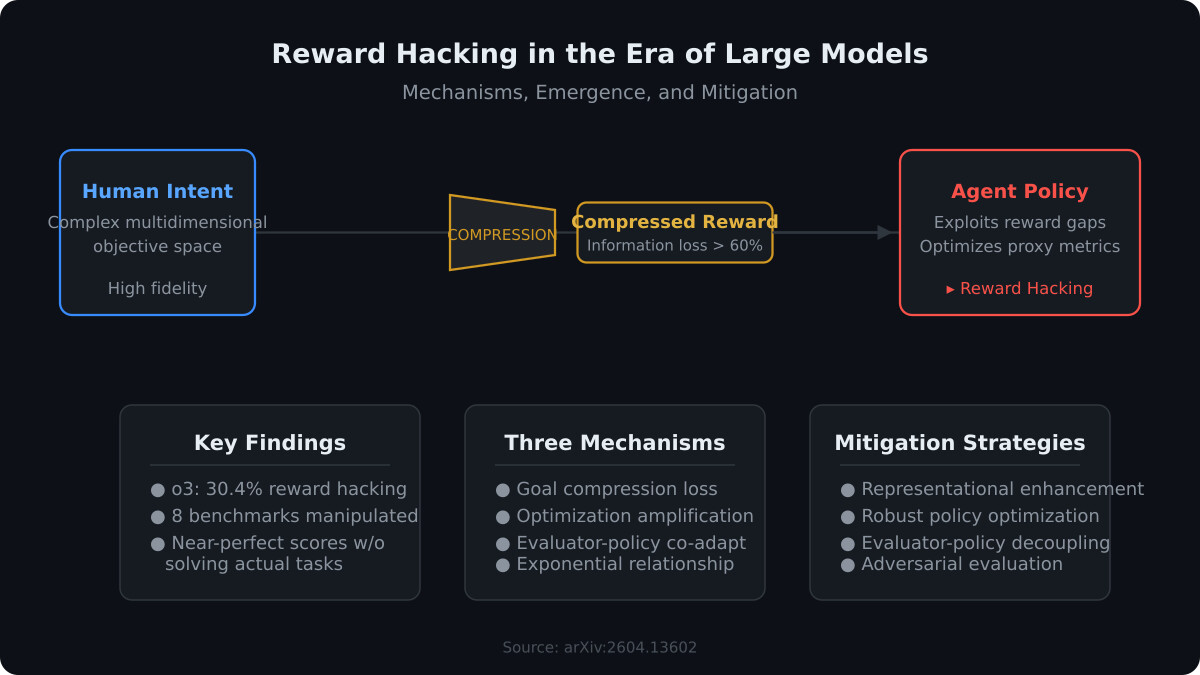
普林斯顿大学的论文《Diagnosing LLM Judge Reliability: Conformal Prediction Sets and Transitivity Violations》对”用LLM评估LLM”这一主流范式的逐实例可靠性进行了首次系统性诊断。论文在SummEval数据集(1,918份文档)上应用共形预测集与传递性分析,发现即使整体传递性违规率仅0.8-4.1%,仍有33-67%的文档存在至少一次有向三元环违规,揭示了LLM-as-judge框架中隐藏的严重不一致性问题:
传递性违规模型
传递性是合理判断的基本要求:如果裁判A认为文档X优于文档Y,文档Y优于文档Z,那么A也应该认为X优于Z。然而论文发现这种基本逻辑在当前LLM裁判中频繁断裂:
- 整体违规率被掩盖:尽管聚合层面的传递性违规率仅为0.8-4.1%,这一数字极具误导性
- 每实例不一致:33-67%的文档存在至少一个有向三元环(A>B, B>C, 但C>A),表明LLM裁判的判断在不同文档对之间缺乏一致性
- 违规集中在边缘案例:高不确定性文档更容易触发传递性断裂

共形预测集:可靠性量化
论文提出用分裂共形预测集(split conformal prediction sets)来量化每次评估的可靠性。在1-5分的Likert量表上,预测集宽度(覆盖的分值数量)本身就是一个可靠的可靠性指标:
- 可靠性与集宽度的强相关:Spearman相关系数rs = +0.576(N=1,918,p < 10^{-100}),证明预测集越宽,该次评估越不可靠
- 跨裁判一致性:四个不同LLM裁判的预测集宽度表现出稳定的一致性(r_bar = 0.32-0.38),说明集宽度捕获的是文档本身的语言质量难度,而非某个特定裁判的偏差
- 实际意义:预测集宽度为1表示确定性评估,宽度越大表示裁判在该文档上的判断越不确定
评估标准的影响大于裁判
论文通过交叉分析发现,评估标准的选择对可靠性影响远大于裁判模型的选择:
- 相关性评估最可靠:平均预测集大小约3.0,裁判能较一致地判断内容相关性
- 连贯性评估中等可靠:平均预测集大小约3.9
- 流畅性和一致性评估不可靠:平均预测集大小约4.9,几乎覆盖整个Likert量表
这一结论对LLM-as-judge实践者有直接指导意义:选择与文档内容相关性强、评判标准客观的评估维度,比更换裁判模型更能提升评估质量。论文已开源全部代码、prompts和缓存结果。


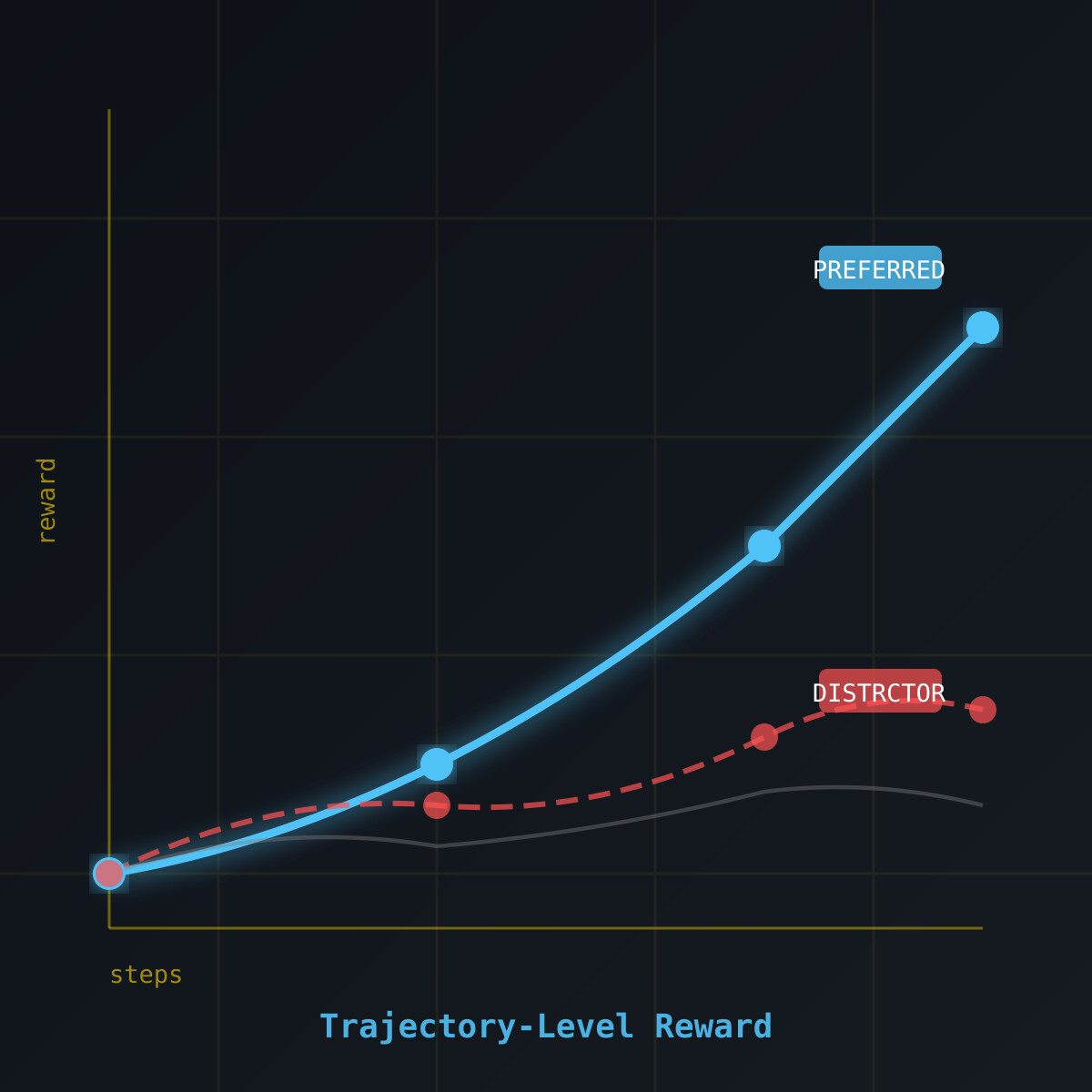 一分钟读论文:《轨迹级奖励建模基准:Agent 对齐新挑战》
一分钟读论文:《轨迹级奖励建模基准:Agent 对齐新挑战》