日本东京大学和美国麻省理工学院的论文 《Aligning Agents via Planning: A Benchmark for Trajectory-Level Reward Modeling》 提出了首个 trajectory-level 的 Agent 对齐偏好基准 Plan-RewardBench,系统性地揭示了当前奖励模型在评估多步行为序列时的能力缺口,为 Agent 对齐技术提供了全新的评估维度。
奖励建模面临的新挑战
在经典的人类反馈强化学习中,Reward Models 是模型对齐的基本信号提供者。随着 LLM 从单轮对话扩展到多轮交互、工具调用和复杂任务规划,reward modeling 的评估对象发生了根本变化:从单步输出转向多步行为序列。
传统 reward modeling 聚焦于单步输出的质量评估,奖励信号主要来源于模型对单个决策点的判断。而 trajectory-level reward modeling 需要评估整个行为序列的整体质量,包括步骤间的连贯性、长期目标的达成度以及多步决策的协调性。
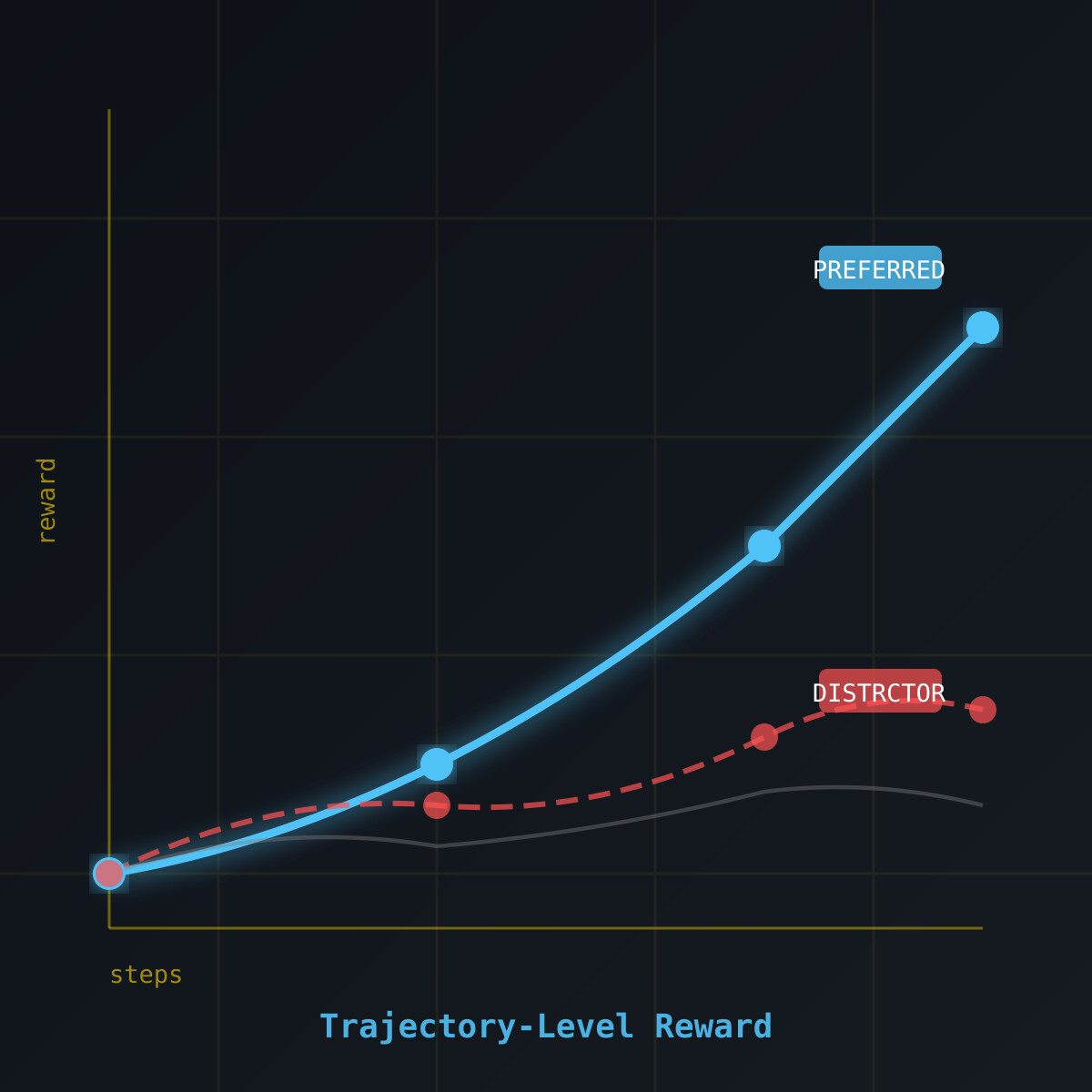
Plan-RewardBench 基准的构建
该研究提出 Plan-RewardBench,一个专门针对 trajectory-level 偏好的评估基准。其核心设计思路是构建复杂工具使用场景下的 agent 轨迹对,包含偏好轨迹与干扰轨迹,要求评判模型做出准确区分。
该基准涵盖了搜索、代码执行、文件操作等多种工具使用场景,具有高度的现实代表性。同时提供了完整的训练数据和评估指标,为后续研究提供了可复现的基准。
评估器的系统性缺陷
该研究对三类主流评估器家族进行了系统性测试。RM-based 评估器主要面向单步输出设计,难以捕捉多步行为序列的整体质量。LLM-as-a-Judge 评估器虽在单轮推理中表现出色,但难以有效权衡多步决策的连贯性与长期目标的一致性。
混合评估器同样未能突破瓶颈,说明当前混合策略未能有效融合各自优势。实验数据显示,在复杂工具使用和长序列任务中,传统方法与人类偏好之间的相关性显著下降,而 trajectory-level 评估方法则展现出更好的对齐效果。


 一分钟读论文:《Meerkat:发现基准测试中 4 倍安全漏洞》
一分钟读论文:《Meerkat:发现基准测试中 4 倍安全漏洞》