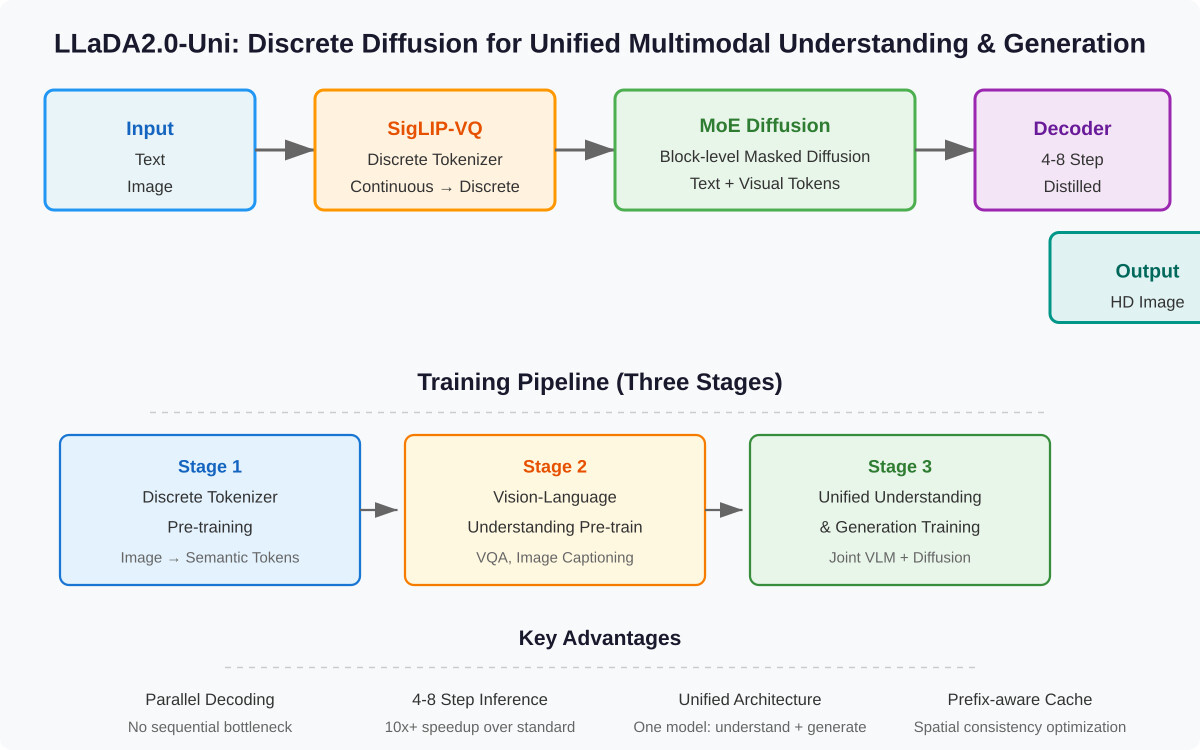
蚂蚁集团 InclusionAI 的论文《LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model》,提出用离散扩散语言模型统一视觉理解和图像生成两个任务。传统AI系统存在”分裂大脑”问题——理解用VLM、生成用扩散模型,需要拼接多个专用模型。LLaDA2.0-Uni的核心思路是将图像压缩为离散语义token,让同一个MoE扩散模型同时处理文本和视觉token。
统一架构设计
论文的核心创新在于离散扩散统一范式。传统多模态系统中,视觉理解(VLM)和图像生成(扩散模型)是两个独立的组件,各自需要不同的架构和训练数据。LLaDA2.0-Uni通过三个组件实现统一:
离散Tokenizer(SigLIP-VQ):将图像压缩为语义token序列,将连续像素空间映射到离散符号空间,使图像数据在表示层面与文本token对称。
MoE离散扩散主干:采用混合专家架构,通过block-level masked diffusion同时处理文本和视觉token,消除自回归方向性偏见。
扩散解码器:通过4-8步蒸馏将离散token重建为高清图像,相比标准扩散模型所需的20-50步,推理速度提升10倍以上。
关键技术突破
并行解码:传统扩散模型按序列逐步生成,LLaDA2.0-Uni利用block-level masked diffusion实现token并行解码,消除序列预测瓶颈,图像生成加速显著。
Prefix-aware缓存:利用图像空间一致性优化推理过程,在生成过程中缓存已解码的prefix信息,减少冗余计算。
蒸馏加速:标准扩散模型需要20-50步去噪才能达到可用质量,论文通过知识蒸馏将解码器压缩至4-8步,在保持图像质量的同时大幅提升推理效率。
训练策略与性能
论文采用三阶段训练策略:首先训练离散tokenizer的预训练,然后进行视觉-语言理解预训练,最后进行统一理解与生成的联合训练。这种渐进式训练方式避免了多任务联合训练中的任务冲突问题。
性能评估显示,LLaDA2.0-Uni在视觉理解任务(图像描述、VQA)上媲美专用VLM,在图像生成和编辑任务上媲美专用文生图模型。其独有优势在于理解-生成-推理的连续交互能力——这是统一架构带来的天然优势,分裂系统无法实现这种无缝切换。


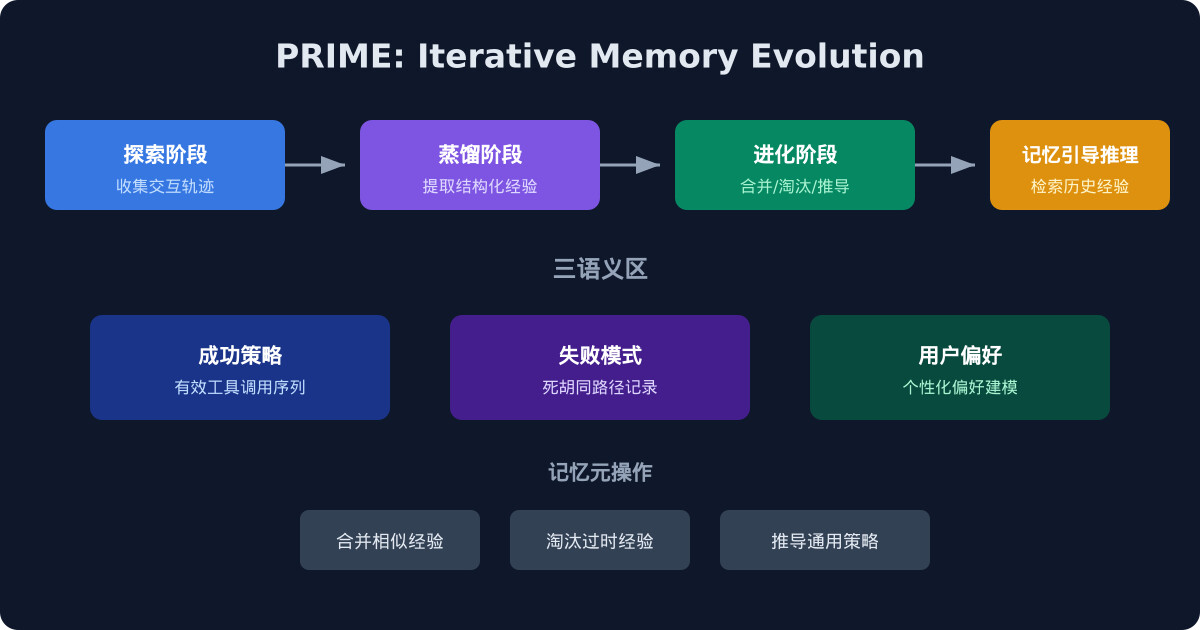 一分钟读论文:《PRIME:通过迭代记忆进化实现用户中心Agent的主动推理》
一分钟读论文:《PRIME:通过迭代记忆进化实现用户中心Agent的主动推理》