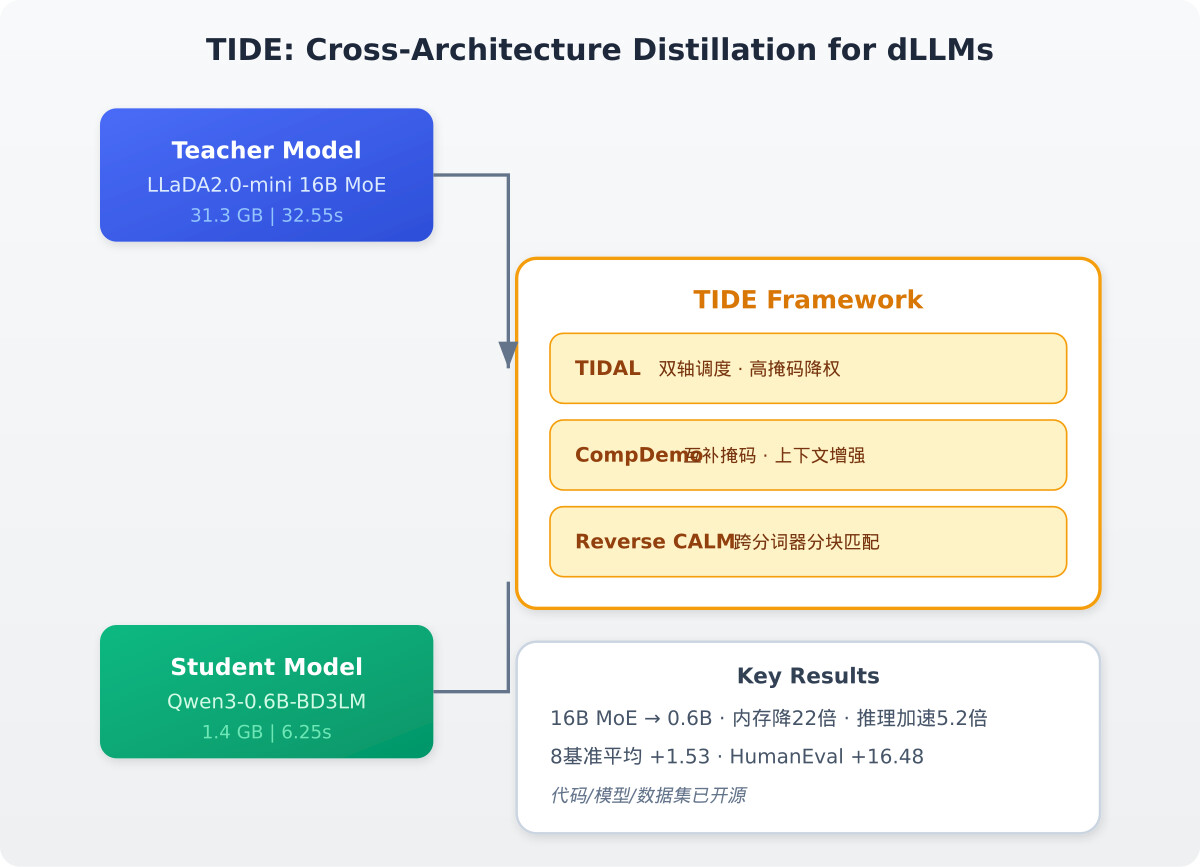
北京大学和浙江大学合作的一篇论文《Turning the TIDE: Cross-Architecture Distillation for Diffusion Large Language Models》,首次实现了扩散语言模型(dLLM)的跨架构蒸馏,将16B MoE教师模型压缩到0.6B学生模型,峰值内存降低22倍、推理加速5.2倍:
扩散语言模型的蒸馏难题
扩散语言模型使用扩散过程对文本进行建模,与传统的自回归(AR)模型不同,dLLM支持并行解码和双向上下文理解,在多项基准上展现出与AR模型相当甚至更优的性能。然而,现有dLLM需要数十亿参数才能达到有竞争力的性能,难以在消费级硬件上部署。
知识蒸馏是压缩大模型的有效方法,但dLLM的蒸馏面临一个根本挑战:跨架构蒸馏。现有蒸馏方法仅限于同一架构内的步数压缩,当教师和学生模型在架构、注意力机制和分词器上存在差异时,token无法直接对齐。TIDE框架通过三个核心组件解决了这一难题。
TIDE的核心方法
TIDE框架包含三个关键设计。
TIDAL调度机制在训练进度和扩散时间步两个维度上联合调节蒸馏强度。当掩码比率较高、教师模型输出不可靠时,TIDAL自动降低该时间步的蒸馏权重,避免学生模型从噪声信号中学习。
CompDemo上下文增强通过两次教师推理,生成互补的掩码分割,让每个掩码位置看到约50%的已揭示上下文。这显著提高了高噪声区域教师信号的质量。
Reverse CALM跨分词器匹配解决了最核心的跨分词器对齐问题。由于教师和学生使用不同分词器,token无法直接对应。Reverse CALM采用反向分块级二元交叉熵,将教师和学生输出按分块进行概率匹配,梯度系数仅依赖固定的教师模型,并加入双端噪声过滤。
TIDE支持两种蒸馏管线:跨分词器管线(LLaDA2.0-mini 16B MoE到Qwen3-0.6B-BD3LM)和共享分词器管线(WeDLM-8B到Qwen3-0.6B-BD3LM)。
关键结果
在8个基准测试上,TIDE-Cross相比未蒸馏的BD3LM基线平均提升1.53分(34.20 vs 32.67)。其中HumanEval代码生成任务提升16.48分(48.78 vs 32.30),蒸馏后的dLLM在代码生成上表现尤为突出。
相比16B MoE教师模型,蒸馏后的0.6B学生模型峰值内存降低22倍(1.4 GB vs 31.3 GB),推理速度提升5.2倍(6.25秒 vs 32.55秒,生成256 token,H100)。将16B MoE和8B Dense教师压缩到0.6B学生模型,仍保持竞争力性能。
意义与展望
TIDE让扩散语言模型从实验室走向消费级硬件部署成为可能。随着dLLM研究的深入,跨架构蒸馏方法有望推动更多大模型在移动设备上的应用。论文的代码、模型和数据集已在GitHub和HuggingFace开源。


 一分钟读论文:《Agent实现AlphaZero流水线》
一分钟读论文:《Agent实现AlphaZero流水线》