layout: post author: unbug title: “一分钟读论文:《Google Titans + MIRAS:终结 AI 健忘症,让模型拥有真正的长期记忆》” categories: [AI] tags: [Google, Titans, MIRAS, 长期记忆, Transformer, 序列建模]
excerpt: “Google Research 发布了 Titans 架构和 MIRAS 框架,通过深度学习的记忆模块和在线优化理论,让 AI 模型能够处理超大规模上下文,终结了 LLM 的健忘症问题。”

引言
2017 年 Transformer 架构的诞生,用注意力机制彻底改写了序列建模的游戏规则。但这个革命性的架构有个致命软肋——计算成本随序列长度呈二次方暴涨。想让 AI 读完整本书、分析整条基因组?对不起,算力钱包撑不住。
现在,Google Research 扔出了王炸:Titans 架构和MIRAS 框架。这对黄金组合把 RNN 的速度和 Transformer 的准确度捏合在一起,让 AI 能实时更新核心记忆,轻松吃下数百万 token 的超长上下文。
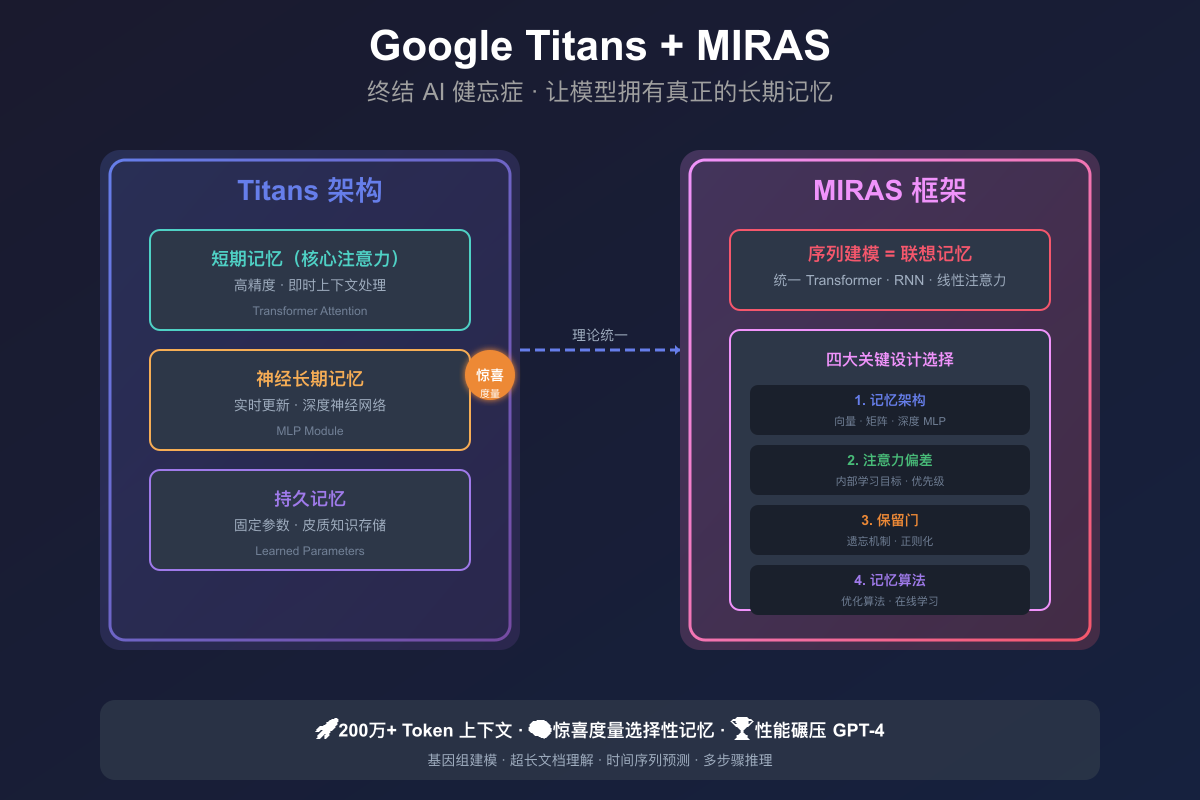
Titans:给 AI 装个真正的长期记忆
Titans 的设计灵感,直接抄了人类大脑的作业——我们大脑本来就有清晰的短期记忆和长期记忆分工。
三层记忆架构
Titans 照搬了这个思路:
- 短期记忆(核心注意力):标准的 Transformer 注意力,高精度抓即时上下文
- 神经长期记忆:一个深度神经网络(多层感知机)模块,推理时实时更新参数
- 持久记忆:固定的学习参数,存着模型的”皮质知识”
惊喜度量:只记重要的事
Titans 最妙的设计,是这个“惊喜度量”(surprise metric)。这跟人类心理学简直一模一样——日常琐事转头就忘,但意外、惊喜、情绪冲击大的事,能记一辈子。
在 Titans 里,惊喜度量就是模型发现当前记忆和新输入之间差得太大:
- 低惊喜:新输入是”猫”,模型记忆里已经预期到是个动物词,梯度(惊喜)很低,直接跳过不记
- 高惊喜:模型正在总结严肃的财务报告,突然冒出来一张香蕉皮的图片(什么鬼?),梯度(惊喜)直接拉满——这玩意儿重要,必须优先存进长期记忆
模型用这个内部误差信号(梯度)当数学版的”卧槽,这很意外!”,让 Titans 能选择性地只更新那些最新颖、最打破上下文的信息,既快又高效。
动量和遗忘机制
Titans 还加了两个关键 buff:
- 动量:同时看”瞬时惊喜”(当前输入)和”过去惊喜”(最近的上下文流),确保相关的后续信息也能被抓住,哪怕单独看这些 token 没啥惊喜
- 遗忘(权重衰减):处理极长序列时,记忆容量有限怎么办?Titans 用自适应权重衰减当遗忘门,该扔的就扔,绝不恋栈
MIRAS:序列建模的统一理论框架
如果说 Titans 是干活的工具,那 MIRAS 就是顶层设计的蓝图。它从更高维度把各种序列建模方法统一了起来。
序列建模 = 联想记忆
MIRAS 的核心洞察是:所有序列建模的重大突破——从现代 Transformer 到新型闪电般的线性 RNN——本质上都是一回事:一个高度复杂的联想记忆模块。
MIRAS 把序列模型拆解成四个关键设计选择:
- 记忆架构:存信息的结构(向量、矩阵,或者 Titans 那种深度多层感知机)
- 注意力偏差:模型优化的内部学习目标,决定优先记什么
- 保留门:记忆正则化器,MIRAS 把”遗忘机制”重新解释成一种特定的正则化,平衡新学习和旧知识保留
- 记忆算法:更新记忆用的优化算法
跳出均方误差的框框
几乎所有成功的现有序列模型,都靠均方误差(MSE)或点积相似度来实现偏差和保留。但这会让模型对异常值敏感,还限制了表达能力。
MIRAS 直接跳出了这个框框,提供了一个生成框架去探索更丰富的设计空间——从优化和统计学文献里借灵感。这就可以创造出有非欧几里得目标和正则化的新架构。
用 MIRAS,Google 造了三个特定的无注意力模型:
- YAAD:对主要错误或”异常值”(比如大文档里的单个拼写错误)不那么敏感。用更温和的数学惩罚(Huber 损失)处理错误,不会对一次性问题反应过度
- MONETA:探索用更复杂、更严格的数学惩罚(广义范数),研究用这些更有纪律的规则处理模型关注和遗忘的内容,能不能整体上得到更强、更稳定的长期记忆系统
- MEMORA:专注于最佳记忆稳定性——强制记忆表现得像严格的概率图。用这个约束,确保每次更新记忆状态时,变化都是受控且平衡的
实验结果:把现有模型按在地上摩擦
Google 研究团队做了严格的实验,把 Titans 和 MIRAS 变体(YAAD、MONETA、MEMORA)跟一众顶尖架构比了个遍,包括 Transformer++、Mamba-2 和 Gated DeltaNet。
语言建模和常识推理
在标准语言建模数据集(C4、WikiText)和零样本推理任务(HellaSwag、PIQA)上,Titans 架构的准确度和困惑度全程领跑。
深度记忆的威力
消融研究把话说得很明白:记忆架构的深度太关键了。同样大小但深度不同的长期记忆模块比起来,深度更深的那个,语言建模的困惑度始终更低。而且缩放特性更好——序列长度大幅增加时,性能照样稳得住。
超长上下文召回
这些新架构最牛的地方,还是处理极长上下文的能力。在 BABILong 基准测试上表现得淋漓尽致——这个任务需要在极长文档里分散的事实之间做推理。在这个挑战性环境里,Titans 把所有基线都干翻了,包括 GPT-4 这种超大型模型,哪怕它参数少得多。Titans 还展示了能有效缩放到超过 200 万个 token 的上下文窗口大小。
应用场景:从文本到基因组,通吃
Titans 和 MIRAS 的应用范围,远不止文本那点事:
- 基因组建模:直接处理完整 DNA 序列,做基因分析和预测
- 时间序列预测:金融市场、天气预报、工业监控,都能上
- 超长文档理解:法律合同、科学论文、历史档案,轻松读
- 多步骤推理:复杂问题解决、代码理解、数学证明,都在行
总结:序列建模的新纪元
Titans 和 MIRAS 框架的登场,标志着序列建模的重大飞跃。用深度神经网络当记忆模块,数据进来时边学边记,这些方法直接突破了固定大小循环状态的局限。
而且,MIRAS 提供了强大的理论统一,揭示了在线优化、联想记忆和架构设计之间的联系。跳出标准的欧几里得范式,这项研究为新一代序列模型打开了大门——把 RNN 的效率,和长上下文 AI 时代需要的表达能力,完美结合在一起。
这可不是又一个架构小改进——这是 AI 记忆系统的范式转移,让我们离真正能理解和处理大规模信息的 AI,又近了一步。


 一分钟读论文:《量子储层计算重大突破!在多体混沌边缘实现最佳性能,为量子AI开辟新道路!》
一分钟读论文:《量子储层计算重大突破!在多体混沌边缘实现最佳性能,为量子AI开辟新道路!》