想象一下:你花了几个月训练了一个全能的大语言模型,它会做数学题、懂编程、还能写优美的文章。然后你想让它专门学会做客服——结果微调之后,它突然连基本的算术都不会了!
这就是 AI 领域著名的灾难性遗忘(Catastrophic Forgetting)问题:当大语言模型在特定任务上微调时,往往会丢失原有的通用知识和推理能力。
有没有什么简单的方法,能让模型在学习新技能的同时,牢牢记住旧知识?
最新的研究给出了一个令人惊讶的答案:让模型在微调前先”自言自语”一会儿!
背景:灾难性遗忘的难题
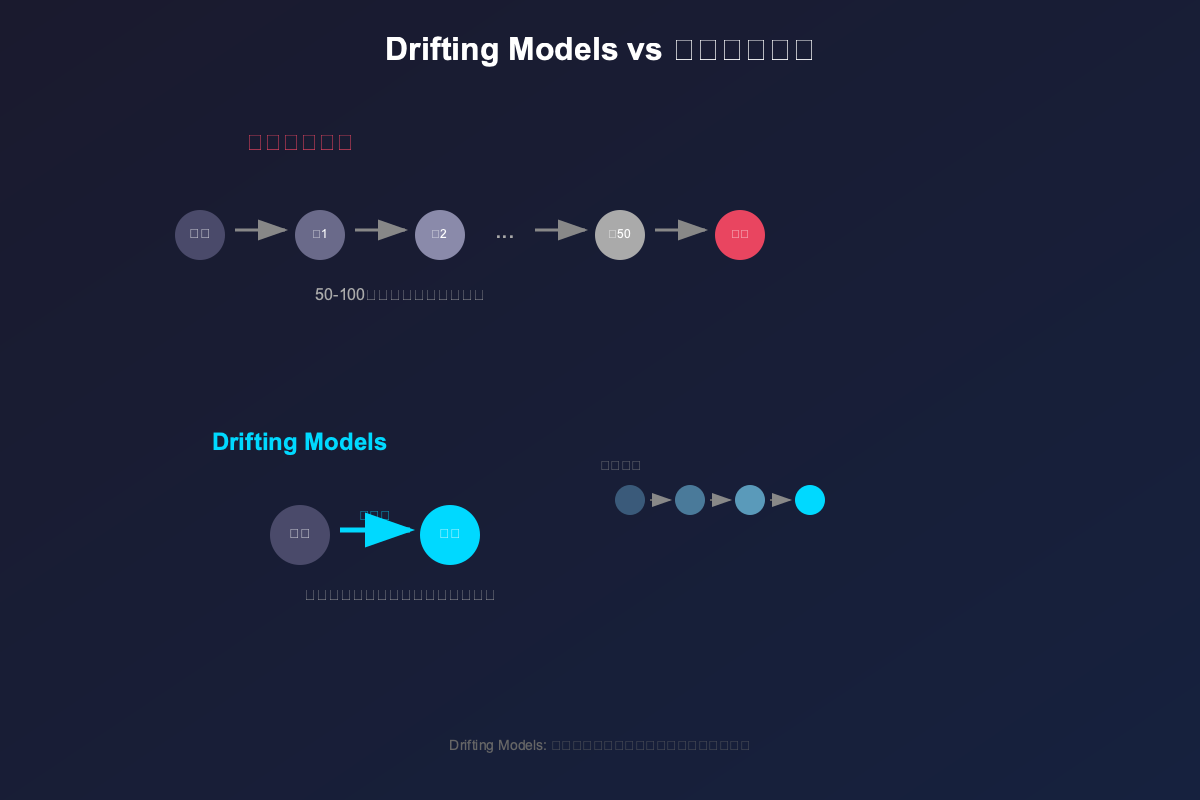
在这个新方法之前,解决灾难性遗忘的方法主要有三类:
1. 数据排练法(Data Rehearsal)
这种方法就像给学生复习旧课本——在微调时混合一些通用领域的数据。但问题是:
- 需要收集或购买大量外部数据
- 这些数据可能和预训练语料不匹配
- 对于不开源预训练数据的模型(如 GPT-4),这方法根本用不了
2. 参数正则化法
这类方法通过约束参数更新来保护重要权重,比如 Elastic Weight Consolidation。但:
- 需要计算和存储每个参数的重要性
- 对于数十亿参数的大模型,内存和计算成本高得离谱
- 实际效果不稳定
3. 启发式方法
比如冻结底层、使用 LoRA 等参数高效微调方法。但:
- 冻结底层会限制模型学习新任务的能力
- LoRA 虽然轻量,但长期训练后仍然会遗忘
这就像教孩子新东西时,要么让他同时抱着一堆旧课本(麻烦),要么把他的大脑锁住一部分(不灵活),要么就让他凑合学(还是会忘)。
核心突破:让模型”自言自语”
这个新方法的核心创新简单得令人惊讶:在微调前,让模型自己生成一些”复习材料”!
工作原理
整个过程只有两步:
第一步:自我对话(Self-Augmentation)
在接触任何下游任务数据之前,先用冻结的基础模型生成一些问答对:
- 模型自己提出问题(比如用 Magpie 或 Crescent 的提示方法)
- 然后自己回答这些问题
- 生成的数据集称为 𝒟self
这就像让学生在考试前,自己给自己出一些复习题并解答——通过这个过程,他会主动回忆和巩固已有的知识。
第二步:混合微调(Mix-in)
把模型自己生成的数据 𝒟self 和任务数据 𝒟task 混合在一起,然后正常微调:
𝒟mix = 𝒟task ∪ 𝒟self
就是这么简单!不需要修改优化器、不需要额外的损失函数、什么都不用改——只需要把模型自己说的话混进去就行。
为什么这方法有效?
研究人员发现了一个惊人的事实:很多灾难性遗忘其实不是知识被”覆盖”了,而是参数被”风格”带偏了!
当你用特定格式的任务数据微调时,模型会为了模仿这些数据的表面形式(比如模板化的指令、重复的标点符号、特定的对话模式)而大幅更新参数。这些更新往往没有语义信息,只是把参数扭向了一个陌生的”风格区域”。
结果就是:模型的参数还在,但它们的”方向”变了,所以原来的知识用不出来了——就像你的钥匙没变,但锁孔被堵住了。
而这个方法的妙处在于:模型自己生成的数据风格和预训练分布完全一致!当这些数据混进去后,优化器的更新就变得更平衡了——来自预训练风格的梯度会抵消任务数据带来的”风格漂移”。
实验结果:惊人的表现
研究团队在 5 个模型、5 个任务、50 个评估场景下进行了全面测试,结果令人震撼:
主要发现
- 在所有 50 个场景中,这个方法都能缓解遗忘
- 在 40 个场景中,这个方法取得了最佳结果
- 不仅保持了通用能力,还提升了领域内表现
具体数据对比
以 LLaMA3-8B-Instruct 在 GSM8K(数学推理)上的表现为例:
| 方法 | GSM8K 准确率 | 领域内表现 |
|---|---|---|
| 原始模型 | 75.8 | 12.2 |
| 仅任务微调 | 65.6 (下降 10.2) | 50.5 (提升) |
| 冻结底层 | 41.1 (下降 34.7) | 48.7 |
| 混合 Alpaca | 58.4 (下降 17.4) | 43.9 |
| 混合 UltraChat | 67.4 (下降 8.4) | 50.3 |
| 这个新方法 | 74.2 (仅下降 1.6) | 50.8 (最佳) |
可以看到:
- 仅任务微调让数学能力暴跌 10.2 个百分点
- 这个新方法几乎完全保护了数学能力(只下降 1.6)
- 同时还取得了最佳的领域内表现!
更惊人的发现
研究团队做了一个有趣的实验:他们把这个新方法生成数据中所有的数学、逻辑、编程相关内容全部删掉,只保留”纯闲聊”数据。
结果呢?即使没有任何数学内容,这个方法仍然能防止大部分 GSM8K 准确率下降!
这证明了我们之前的理论:这个方法的保护作用主要来自风格对齐,而不是具体知识的复习。只要数据风格对了,哪怕内容无关,也能防止遗忘!
最佳混合比例
实验发现,1:1 的混合比例(任务数据:自生成数据)效果最好——既能最大化通用能力的保持,又不会侵蚀领域内准确率。
实际意义
这个方法的意义不仅仅是技术突破,更在于它的实用性:
1. 无需外部数据
不需要收集、清洗、匹配外部数据集——模型自己就能生成复习材料。对于不开源预训练数据的商业模型,这简直是救星。
2. 几乎零成本
只需要在微调前加一个采样步骤,不需要修改训练框架、不需要调整超参数、不需要额外的计算资源(除了生成数据的推理时间)。
3. 模型无关
在 LLaMA2、LLaMA3、Qwen2.5 等不同架构、不同规模的模型上都有效。
4. 即插即用
可以轻松集成到现有的微调流程中,比如 LLaMA-Factory。
局限性
当然,这个方法也不是万能的:
- 依赖基础模型的生成质量:如果基础模型本身生成能力弱,自对话可能会重复、低质或有偏差。
- 不能解决所有遗忘机制:论文主要针对”风格诱导的参数漂移”,其他类型的遗忘可能还需要其他方法。
- 额外的生成成本:虽然不需要外部数据,但生成自对话还是需要推理时间和存储空间。
结语
这篇论文最令人兴奋的地方在于:它用一个极其简单的想法,解决了一个长期存在的难题。
“让模型自言自语”——这个想法听起来像是天方夜谭,但它却实实在在地奏效了。而且,它背后的理论洞见(”很多遗忘其实是风格漂移”)也让我们对大语言模型的工作原理有了更深的理解。
最重要的是,这个方法是一个立即就能用的方法。你不需要等待新的模型架构,不需要巨额的计算资源,只需要在微调前让模型”自己跟自己聊一会儿”。
灾难性遗忘不再是专业化必须付出的代价——让模型自言自语,就能既学会新技能,又不忘旧知识!
论文信息
- 标题:Talking to Yourself: Defying Forgetting in Large Language Models
- 作者:Yutao Sun, Mingshuai Chen, Tiancheng Zhao, Phillip Miao, Zilun Zhang, Haozhan Shen, Ruizhe Zhu, Jianwei Yin
- 机构:浙江大学、斯坦福大学、ETH Zürich
- 论文链接:https://arxiv.org/abs/2602.20162
- 发表时间:2026 年 2 月


 一分钟读论文:《CATS Net:当 AI 开始像人类一样理解概念,从感官体验到抽象思维的突破!》
一分钟读论文:《CATS Net:当 AI 开始像人类一样理解概念,从感官体验到抽象思维的突破!》