这篇论文在解决什么问题?
如果你用过 AI 做数学题,你可能会发现:有时候 AI 能做对很难的题,但有时候又会在简单题上犯低级错误。这不是因为 AI “笨”,而是因为当前的训练方法还有局限。
核心问题: 现有的强化学习方法(比如 GRPO)虽然能提升 AI 的推理能力,但它们依赖外部的奖励信号,就像学生永远在等老师打分,而不会自己检查作业。
这篇论文的解决方案:iGRPO(Iterative Group Relative Policy Optimization) —— 让 AI 学会”自我反馈”!
iGRPO 是怎么工作的?
想象一下你做数学题的过程:
- 第一阶段(草稿):你先尝试几种不同的解法,选出看起来最靠谱的那个
- 第二阶段(优化):基于你选出来的最佳解法,继续改进和完善
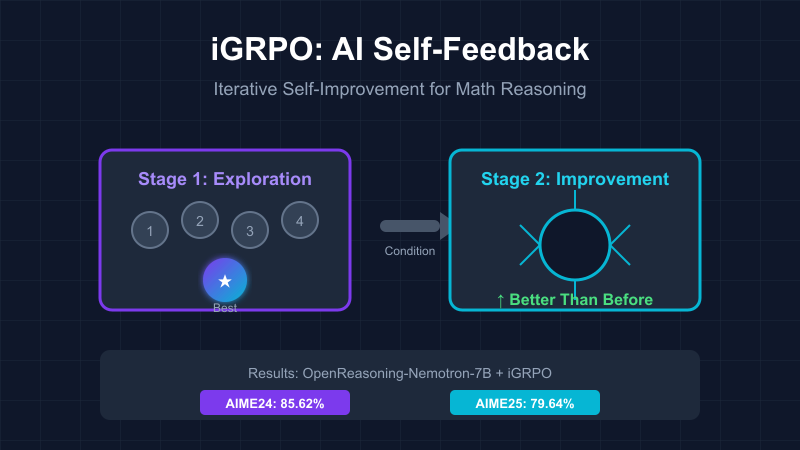
iGRPO 就是这么做的! 它引入了一个两阶段的强化学习框架:
Stage 1:探索与选择
- 模型生成多个候选解决方案
- 根据奖励信号选出最强的那个尝试
- 就像你在草稿纸上试几种方法
Stage 2:条件化改进
- 模型以刚才选出的最佳解法为条件
- 学习如何”超越”自己之前的最佳表现
- 就像你基于正确思路继续完善答案
最酷的是: 不需要额外的批评模型,不需要生成复杂的批评文本,只需要同一个标量奖励!
效果有多好?看看数据!
这篇论文在多个基准测试上都取得了显著提升:
| 模型 | 基准方法 | iGRPO | 提升 |
|---|---|---|---|
| Nemotron-H-8B-Base-8K | 41.1% | 45.0% | +3.96% |
| DeepSeek-R1-Distill-Qwen-7B | 68.3% | 69.9% | +1.6% |
| OpenMath-Nemotron-14B | 76.7% | 78.0% | +1.3% |
最亮眼的结果:
- OpenReasoning-Nemotron-7B + iGRPO 在 AceReason-Math 数据集上:
- AIME24:85.62% 🎯
- AIME25:79.64% 🏆
这可是当前的 state-of-the-art(最先进水平)!
还有什么有趣的发现?
1. 延迟熵崩溃(Entropy Collapse)
强化学习中常见的问题是”熵崩溃”——模型很快就变得过于保守,只输出确定的答案。但 iGRPO 能有效延迟这个过程!
2. 泛化能力强
这个改进框架不局限于 GRPO!论文显示它也能提升 DAPO 和 GSPO 等其他方法。
3. 生成式法官的好处
使用生成式法官(generative judge)能带来额外收益——模型不仅能得到分数,还能理解”为什么”。
为什么这很重要?
- 更可靠的数学推理:对于教育、科研、工程等领域都有实际价值
- 训练效率提升:不需要复杂的外部批评模型,简化了训练流程
- 思路的启发:自我反馈的机制可能适用于更多任务
- 开源可复现:这篇论文的方法基于开源模型,大家都能尝试!
我的一些思考
这篇论文最让我喜欢的地方是:它的核心思想很直观,但效果却很显著。
就像人类学习一样——真正的进步往往来自于”超越自己”,而不是永远等待别人的评价。iGRPO 把这个理念用在了 AI 训练上,结果令人印象深刻。
而且,这篇论文来自 NVIDIA Research,作者团队包括 Ali Hatamizadeh、Shrimai Prabhumoye、Igor Gitman 等知名研究者。实验设计严谨,结果令人信服。
相关链接
- 论文链接:arXiv:2602.09000
- 发布日期:2026 年 2 月
- 机构:NVIDIA Research
如果你对 AI 推理能力的提升感兴趣,这篇论文绝对值得一读!
你觉得这个自我反馈的思路还能用在什么地方?欢迎在评论区分享你的想法!


 一分钟读论文:《Drifting Models:何恺明团队的生成式AI新范式,一步到位秒杀扩散模型》
一分钟读论文:《Drifting Models:何恺明团队的生成式AI新范式,一步到位秒杀扩散模型》