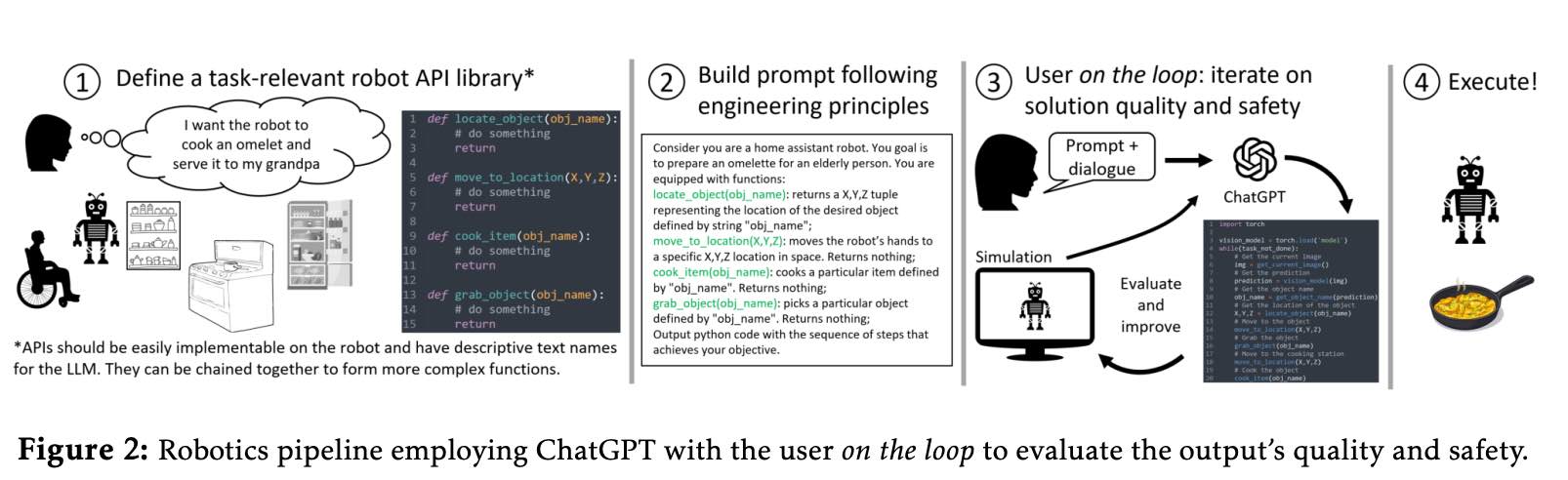
一分钟读论文:GitHub Copilot 的代码生成稳健吗?

📝 论文概览
论文标题:On the Robustness of Code Generation Techniques: An Empirical Study on GitHub Copilot
作者:Antonio Mastropaolo 等 7 位研究者
论文链接:https://arxiv.org/abs/2302.00438
🎯 核心问题
你有没有遇到过这种情况:用同样的需求,换个说法让 AI 写代码,结果生成的代码完全不一样?这篇论文就是研究的就是这个问题——AI 代码生成工具的稳健性。
🔬 研究方法
研究团队测试了 892 个 Java 方法,用了两种复述技术(手动 + 自动,PEGASUS 和 TP),测试了 GitHub Copilot 在不同表述下的表现。
📊 核心发现
1️⃣ 表述不同,结果差异大
- 约 46% 的情况下,语义等价但说法不同的描述,会导致 Copilot 生成完全不同的代码推荐。
2️⃣ 正确性受影响
- 约 30% 的情况下,代码的正确性会因为表述不同而受到影响。
3️⃣ 通过率堪忧
- 只有 约 13% 的实例能生成通过测试的方法。
📈 数据亮点
| 指标 | 数值 |
|---|---|
| 测试方法数量 | 892 个 |
| 代码推荐差异率 | ~46% |
| 正确性受影响率 | ~30% |
| 测试通过率 | ~13% |
| 平均方法长度 | 150 tokens |
| 平均圈复杂度 | 5.3 |
| 中位数圈复杂度 | 3.0 |
💡 一句话总结
AI 代码生成工具还不够稳健——同样的需求,换个说法,结果可能完全不同。在实际使用时要多加小心!
🎓 研究意义
这篇论文提醒我们:虽然 AI 代码生成工具很方便,但它们还不够成熟。在使用时还是要多加验证,不能完全依赖。


 一分钟读论文:《ChatGPT 提示模式:提升代码质量、重构、需求获取和软件设计》
一分钟读论文:《ChatGPT 提示模式:提升代码质量、重构、需求获取和软件设计》