新西兰奥克兰梅西大学数学与计算科学学院的论文《ChatGPT: The End of Online Exam Integrity?》评估了 ChatGPT 执行高级认知任务和生成与人类生成的文本的能力。发现:ChatGPT 能够展现批判性思维能力。
- 这些模型展⽰了⾼度的批判性思维,能够在输⼊很少的情况下⽣成⾼度逼真的⽂本,从⽽使学⽣有可能在考试中作弊。
- ChatGPT 等技术的出现对在线考试的完整性构成了重⼤威胁,尤其是在在线考试越来越普遍的⾼等教育背景下。
- 恢复监考和⼝试以及使⽤先进的监考⼯具可能会有效应对这种威胁。
- 需要研究能够检测来⾃类似 ChatGPT 模型的⽂本输出的新⼈⼯智能和机器学习⼯具。
评估的维度
论文评估的方法:⾸先,要求 ChatGPT ⾃⾏⽣成涉及场景的批判性思维疑难题例题,⾯向各学科本科⽣。其次,ChatGPT 被要求提供对问题⽣成的答案。最后,ChatGPT 被要求批判性地评估对问题的回答。
相关性:对答案的批判性评估,所有这些都明显与提⽰相关,所有的回答都是切题的,并且与每个学科的主题和请求的意图相关。清晰度:ChatGPT 表现出很强的清晰度。响应中使⽤的语⾔简单易懂,并遵循⼈们对⾃然语⾔响应的预期结构和惯例。答复组织良好且连贯,较⻓的⽂本中有意表达想法。准确性:对过度拟合的概念进⾏了很好的描述,并准确提供了可⽤于解决该问题的技术⽰例。精确:对问题的回答既具体⼜详细。深度:ChatGPT 在制定的问题的复杂性以及⽀持这些问题的理由⽅⾯表现出了值得注意的深度。⼴度:所提供的答案在每种情况下都提供了两种情景的解释。每种情况下的改进建议都提供了⼴度能⼒的进⼀步⽰例。逻辑:所有回答都遵循逻辑和⼀致的推理,提供具体的例⼦和解释。说服⼒:论点和证据以清晰和合乎逻辑的⽅式呈现,并提及为解决潜在的反驳或异议所做的努⼒。独创性:在完整呈现的意义上不⼀定是原创的或新颖的新想法,他们提供看似有⽤的信息和⻅解,⾜以回答本科考试。


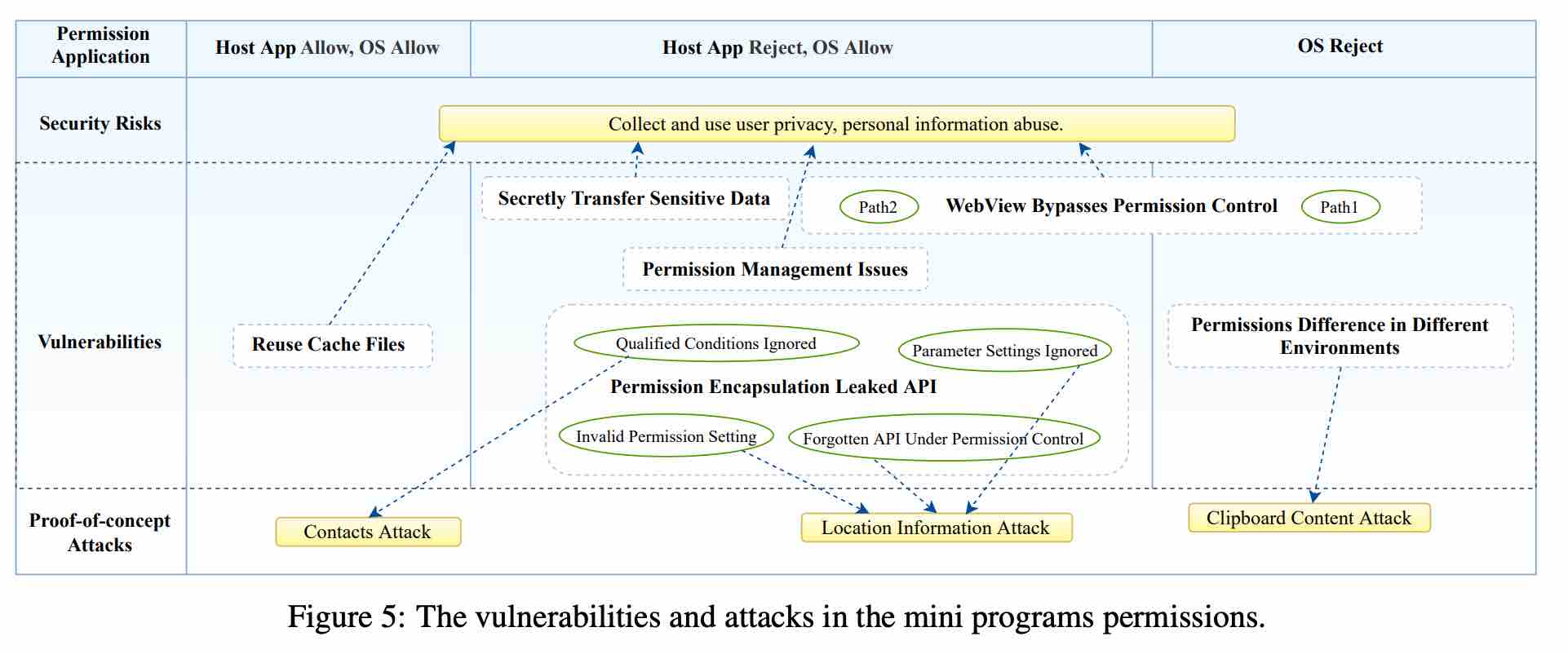 一分钟读论文:《细孔沉千帆:小程序权限漏洞研究》
一分钟读论文:《细孔沉千帆:小程序权限漏洞研究》