LUCID Attention:给长上下文模型戴上”降噪耳机”
想象一下:你在一个嘈杂的咖啡馆里,试图听清朋友说的话。周围的人声、音乐声、咖啡机的声音混杂在一起,让你很难集中注意力。
这就是今天长上下文语言模型面临的困境。
2026 年 2 月,来自德克萨斯大学奥斯汀分校和 Google 的研究团队发布了一篇重要论文:“LUCID: Attention with Preconditioned Representations”。这篇论文提出了一种全新的注意力机制,给模型戴上了一副”降噪耳机”,让它能在超长上下文中精准地找到真正重要的信息。
问题背景:注意力机制的”两难选择”
自 2017 年 Transformer 架构诞生以来,softmax 注意力机制一直是其核心组件。它就像一个”智能放大镜”,帮助模型从输入序列中找到相关的信息。
但是,随着语言模型需要处理的上下文越来越长——从几千 token 到几十万甚至上百万 token——这个”智能放大镜”开始出问题了。
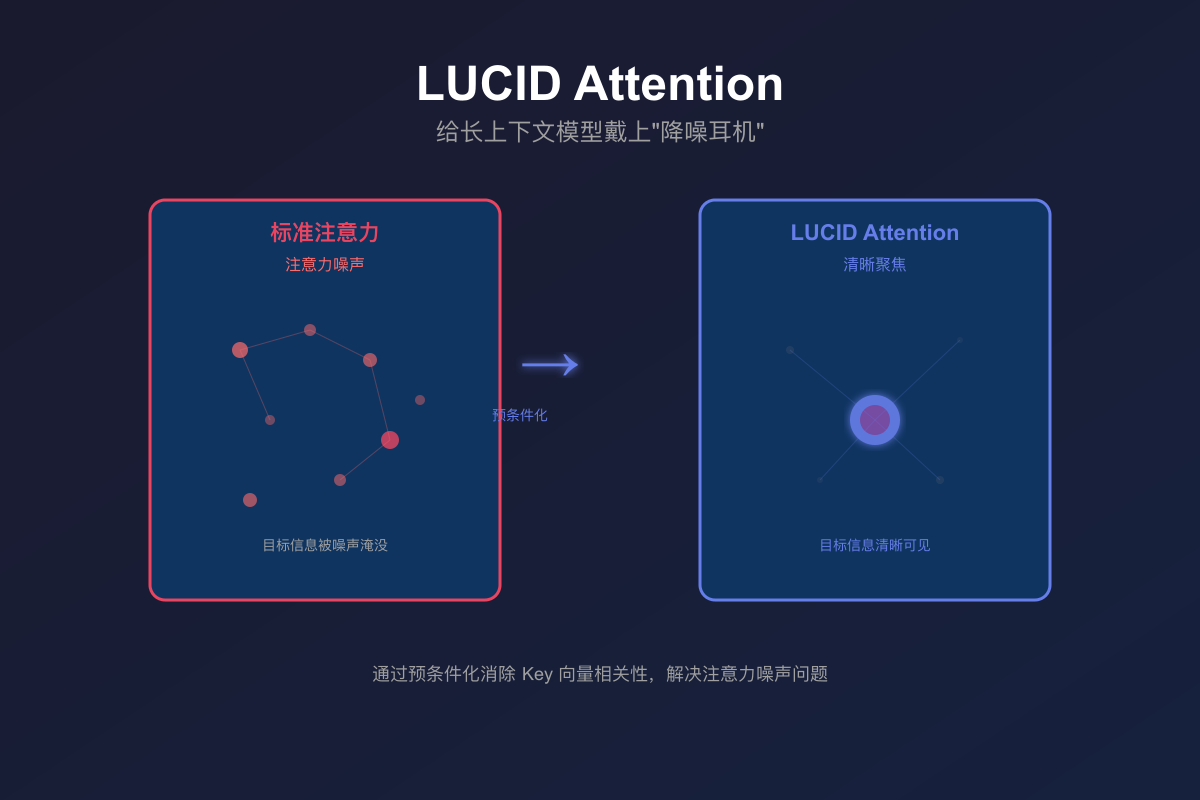
问题一:注意力噪声——”听不清重点”
标准 softmax 注意力有个毛病:它必须把注意力分配给所有位置,哪怕大部分位置都是无关的。
想象一下,你要在一本 10 万字的小说里找某个特定人物的名字。标准注意力就像是把注意力平均分给了每一个字,而不是直接聚焦到那个名字上。
结果就是:真正重要的信息被稀释了,模型”听不清重点”。
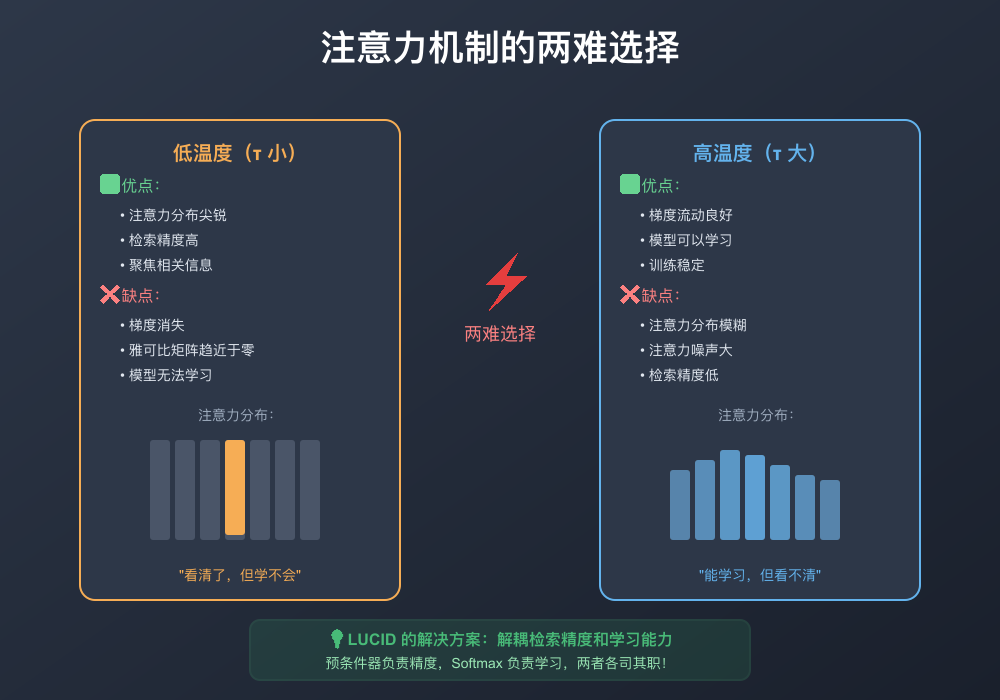
问题二:可学习性困境——”看清了就学不会”
为了解决这个问题,研究人员想了个办法:降低 softmax 的温度,让注意力分布更尖锐。这就像是把放大镜的焦距调得更小,让焦点更集中。
但是,这又带来了新问题:当注意力分布变得太尖锐时,梯度就消失了。模型无法继续学习,就像一个学生一旦认定了某个答案,就再也听不进其他意见了。
于是,我们陷入了一个经典的”两难选择”:
- 要么注意力模糊,但能继续学习
- 要么注意力精确,但无法继续学习
LUCID 的核心洞察:从根源解决问题
LUCID(LUcid Preconditioned Attention)的核心洞察非常简单但深刻:注意力噪声的根源是 key 向量之间的相关性。
这是什么意思呢?让我们用一个比喻来解释。
想象你在一个鸡尾酒会上,每个人都在说话。如果每个人的声音都很相似(高度相关),你就很难分辨出你想听的那个人的声音。但如果每个人的声音都很独特(不相关),你就能很容易地聚焦到你想听的那个人。
LUCID 做的事情,就是让每个 key 向量都变得”独特”,消除它们之间的相关性。
核方法视角:重新理解注意力
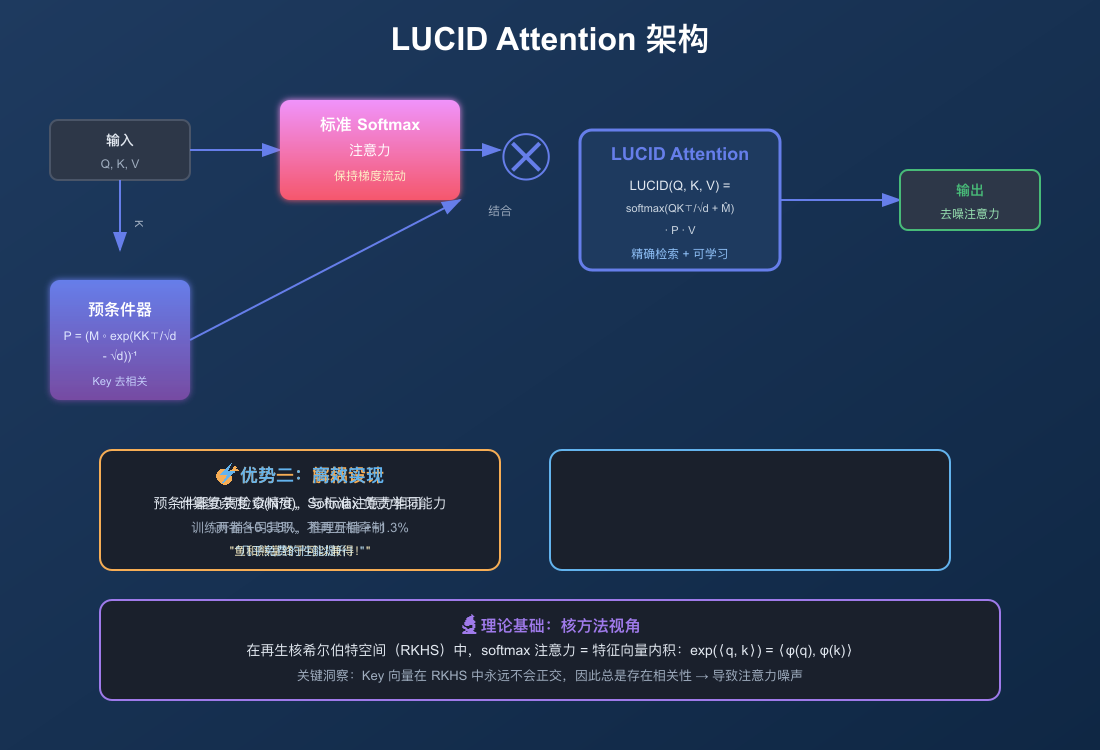
研究团队从核方法(Kernel Methods)的角度重新审视了注意力机制。在再生核希尔伯特空间(RKHS)中,softmax 注意力可以被看作是特征向量的内积:
exp(⟨q, k⟩) = ⟨φ(q), φ(k)⟩
关键发现是:在这个高维特征空间中,key 向量永远不会正交——它们总是存在一定程度的相关性。这就导致了注意力噪声。
解决方案:预条件化——给 key 向量”去相关”
LUCID 的解决方案是构建一个预条件器,在高维特征空间中对 key 向量进行去相关处理:
P = (M ◦ exp(KK⊤/√d - √d))⁻¹
这个预条件器就像是一个”信号处理器”,它会分析所有 key 向量之间的关系,然后消除它们之间的相关性。
然后,LUCID 将标准注意力权重与这个预条件器结合起来:
LUCID(Q, K, V) = softmax(QK⊤/√d + M̂) · (M ◦ exp(KRNK⊤RN/√d - √d))⁻¹ V
技术突破:鱼和熊掌可以兼得
LUCID 最关键的突破是:它把检索精度和学习能力完全解耦了。
突破一:各司其职
在 LUCID 中:
- 预条件器负责实现精确的检索——它让 key 向量变得独特,让查询能精准地找到相关信息
- Softmax在标准温度下工作——它保持良好的梯度流动,让模型能继续学习
这样一来,鱼和熊掌终于可以兼得了!模型既可以获得精确的注意力分布,又不会遇到梯度消失问题。
突破二:效率几乎不受影响
你可能会想:增加了这么复杂的预条件化步骤,计算开销肯定很大吧?
恰恰相反!LUCID 的计算复杂度仍然保持 O(N²d),与标准注意力相同。这得益于:
- 使用高度优化的 cuBLAS TRSM(三角求解)内核
- 利用因果掩码的下三角结构进行高效前向替换
- 训练开销仅增加 0-5.5%,推理开销仅约 1.3%
换句话说,LUCID 几乎是”免费”的!
突破三:KV Cache 优化
对于自回归解码,LUCID 还设计了增量式的预条件器计算方法,使得推理开销几乎可以忽略不计。
实验结果:效果惊人!
研究团队在多个长上下文基准测试中验证了 LUCID 的效果,结果令人印象深刻。
实验一:多针检索任务——从 11.4% 到 37.4%
“多针检索任务”就像是在一个干草堆里找多根针。结果显示:
| 配置 | 标准注意力 | LUCID | 提升 |
|---|---|---|---|
| 2 针,2K 序列 | 74.2% | 76.6% | +2.4% |
| 6 针,2K 序列 | 38.8% | 43.6% | +4.8% |
| 多针,长序列 | 11.4% | 37.4% | +26.0% |
在最困难的配置下,LUCID 的准确率从 11.4% 提升到了 37.4%——提升了 26 个百分点!
这就像是从”几乎找不到”变成了”大概率能找到”。
实验二:BABILong 长上下文推理——稳定表现
在 32K、64K、128K 三个上下文长度上:
- 标准注意力:从 0.14 下降到接近 0
- LUCID-PaTH:保持在 0.21-0.25,几乎没有下降
这表明 LUCID 能够在超长上下文中稳定地保留对分布式事实的访问能力。
实验三:实际任务性能
在 LongBench 和 SCROLLS 基准测试中:
- HotpotQA:LUCID 取得最佳 F1(0.0862)
- Qasper:LUCID-PaTH 比 PaTH 提升 +1.14 F1
- QMSum:LUCID 取得最佳 ROUGE-L(12.60)
实验四:注意力噪声减少 56.6%
最直接的证据来自注意力权重的变化:在检索任务中,LUCID 将相关 token 的平均注意力权重从 0.1817 提升到 0.2845,相对提升 56.6%!
这直接证明了预条件化有效减少了注意力噪声——模型确实更专注于相关信息了。
与其他方法的对比
| 方法 | 核心思想 | 局限性 |
|---|---|---|
| 差异 Transformer | 两个注意力图的差异 | 只是缓解噪声,未解决根源 |
| DeltaNet | 有限维空间中的预条件化 | key 可能正交,修正消失 |
| PaTH | 基于预条件器的位置编码 | 与 LUCID 正交,可结合使用 |
| LUCID | RKHS 中的 key 去相关 | 无根本性局限 |
LUCID 与 DeltaNet 的关键区别在于特征空间的维度:
- DeltaNet 在有限维 token 空间中操作,key 可能正交
- LUCID 在无限维 RKHS 中操作,exp(k⊤i kj) > 0 始终成立,因此总能提供有意义的修正
实际应用建议
何时使用 LUCID
- 长上下文任务:当序列长度超过 8K 时,LUCID 的优势开始显现
- 精确检索需求:需要从大量干扰信息中准确定位少数关键信息的场景
- 多跳推理:需要在长文档中进行多步推理的任务
实现细节
- 使用 RMS 归一化处理 key 向量,确保预条件器矩阵是单位对角的
- 利用分组查询注意力(GQA)进一步减少开销
- 对于超长上下文,可以与滑动窗口或 SSM 层混合使用,LUCID 专注于提升全局注意力层的精度
与其他技术的结合
LUCID 的设计使其可以与多种现有技术互补:
- RoPE:实验表明,RoPE 能增强 LUCID 的效果
- PaTH:LUCID-PaTH 组合实现了最佳的长度外推能力
- Gated Attention:与 Affine-Scaled Attention 类似,门控机制可以进一步提升性能
理论意义
LUCID 的贡献不仅仅是工程上的改进,更具有重要的理论意义:
- 核方法视角:将注意力机制与核方法理论联系起来,为理解注意力提供了新的数学框架
- 预条件化在深度学习中的应用:展示了如何将数值线性代数中的经典技术应用于神经网络架构设计
- 无限维特征空间的利用:证明了在无限维 RKHS 中操作可以带来实际的性能提升
未来方向
论文指出了几个值得探索的未来方向:
- 双向模型扩展:当前设计主要针对因果语言模型,如何将预条件化应用于扩散模型等双向场景
- 与高效注意力的混合:结合线性注意力的效率和 LUCID 的精度
- 理论分析:更深入地理解 RKHS 中去相关的几何意义
- 更大规模验证:在千亿参数模型上验证 LUCID 的效果
结论
LUCID Attention 代表了 2026 年初注意力机制研究的一个重要突破。通过从核方法的角度重新审视注意力问题,并巧妙地应用预条件化技术,它成功地解决了长上下文场景中”检索精度”与”可学习性”之间的经典困境。
这篇论文的价值不仅在于提出了一个有效的技术方案,更在于为注意力机制的研究提供了新的理论视角。随着语言模型继续向更长上下文、更复杂推理的方向发展,LUCID 这样的创新将变得越来越重要。
对于实际应用来说,LUCID 的优势在于:
- ✅ 即插即用的替换方案
- ✅ 极小的计算开销
- ✅ 在长上下文中的显著性能提升
- ✅ 与现有技术良好的兼容性
如果你正在构建或优化长上下文语言模型,LUCID Attention 绝对值得关注和尝试!
论文链接:arXiv:2602.10410
作者:Sai Surya Duvvuri, Nirmal Patel, Nilesh Gupta, Inderjit S. Dhillon
机构:德克萨斯大学奥斯汀分校、Google
发布日期:2026 年 2 月 12 日


 HRM 架构突破:用仅 2700 万参数和 1000 个训练样本超越最先进的大语言模型
HRM 架构突破:用仅 2700 万参数和 1000 个训练样本超越最先进的大语言模型